背景介绍
极客大学业务架构实战营课程作业
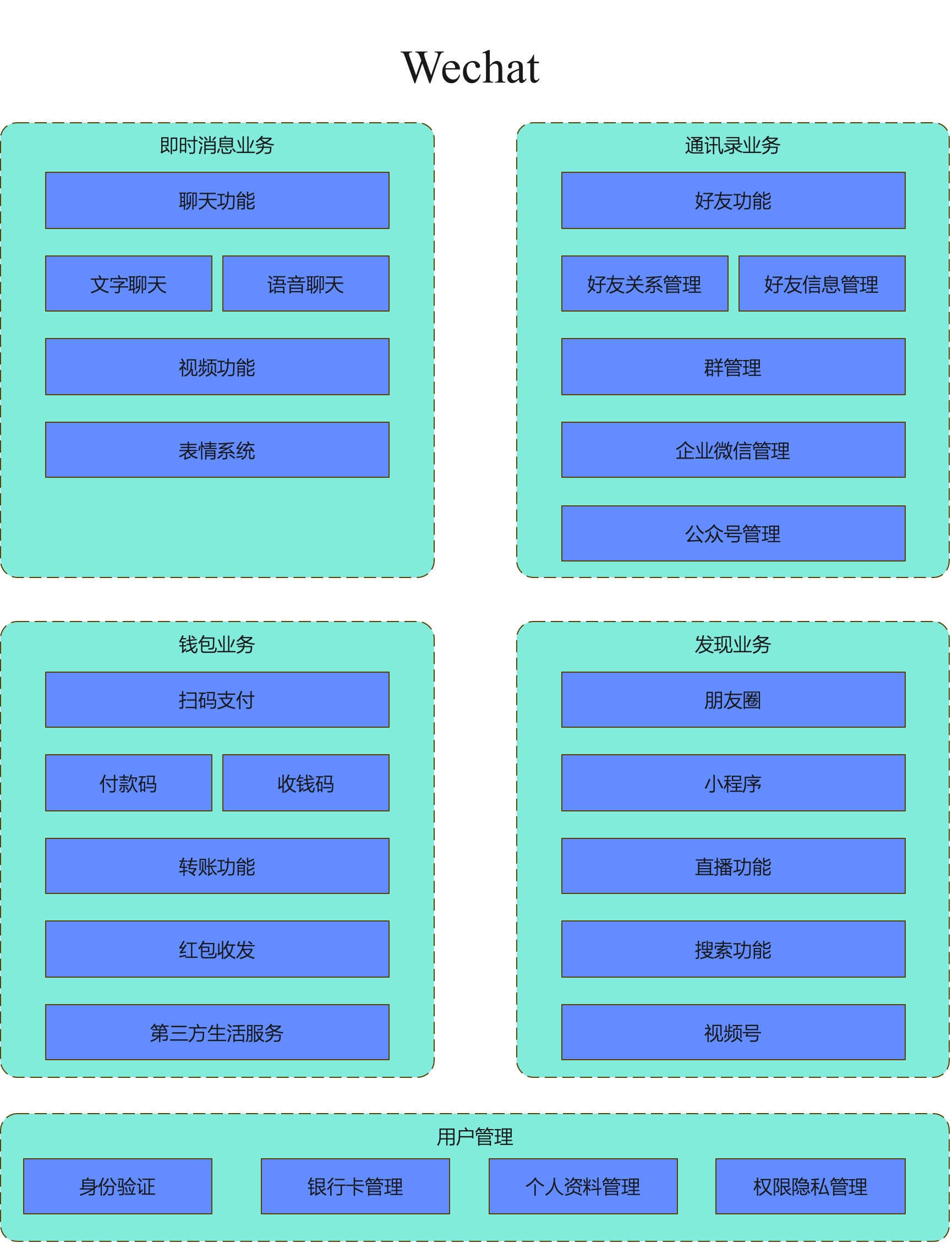
作业1 画出微信的业务架构图
作业内容
画出微信的业务架构图
结果展示
作业2 “学生管理系统”毕设架构设计
作业内容
假设今年学校毕业设计要求提升,要求做真正可运行的学生管理系统,学院对毕设的具体要求如下:
more >>Keep curious to the world, and do cool things that matter.
极客大学业务架构实战营课程作业
画出微信的业务架构图
假设今年学校毕业设计要求提升,要求做真正可运行的学生管理系统,学院对毕设的具体要求如下:
more >>今年3.12,刷公众号时看到腾讯技术推了个很有趣的公益活动,借着植树节的名义,活动名也很有意思叫「码上种树」,点开看了下还有奖励,整个页面上只有一个按钮「点我开始种树」,
这个比较简单,就不介绍了,其实最主要是我没有存界面,找不到原始代码了
这题很简单,没有任何运算,答案在pull的结果里,直接发请求提交即可
最近在面试过程中,连着被问了几次反转链表相关的问题,发现自己虽然知道大体原理,但还是在写到具体细节时会乱掉,加上面试的紧张氛围下,更容易手足无措导致无法正确写出结果,而反转链表是一个非常基础的问题,写不出来会是一个很大的减分
1 | class ListNode(object): |
Easy
Flask是Python下非常流行的一种Web开发框架,但是作为Web框架,Flask又是如何接收来自远程的请求并作出响应的呢,通过查资料、看源码和进行简单的实验,我想弄清楚这样的一个实现过程
Web Server Gateway Interface,以下来自Wikipedia
The Web Server Gateway Interface (WSGI, pronounced whiskey[1][2] or WIZ-ghee[3]) is a simple calling convention for web servers to forward requests to web applications or frameworks written in the Python programming language. The current version of WSGI, version 1.0.1, is specified in Python Enhancement Proposal (PEP) 3333.[4]
WSGI was originally specified as PEP-333 in 2003.[5] PEP-3333, published in 2010, updates the specification for Python 3.
WSGI是用来在web服务器向用Python写的Web应用/框架传递请求的调用约定,在PEP-333/PEP-3333提出,是为了解决各Python程序和web server交互的乱象
在Python中,我们可以使用wsgiref来实现一个简单的web接口
more >>Least Recently Used,在操作系统里是一种常用的页面置换算法,置换策略即,选择最近最久未使用的页面予以淘汰
link: https://leetcode-cn.com/problems/lru-cache/
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制 。 实现 LRUCache 类:
LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存 int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。 void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
Example
more >>事务就是一组原子性的SQL查询,或者说一个独立的工作单元
一个事务必须被视为一个不可分割的最小工作单位,整个事务中所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中一部分
事务总是从一个一致性状态转移到另一个一致性状态
例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不会变的
一个事务所做的修改在最终提交之前,对其他事务是不可见的
more >>单例模式是一种很常见的设计模式,一个类只允许创建一个对象(或者实例),那这个类就是一个单例类
通常我们把__init__称作构造方法,但实际构造实例用的是__new__方法,这是一个特殊的类方法,不需要使用@classmethod装饰器,必须返回一个实例,返回的实例会作为第一个参数(即self)传给__init__方法,而__init__方法调用时需要传入实例,且禁止任何返回值,因此__init__方法其实是初始化方法,真正的构造方法实际是__new__
__new__方法也可以返回其它类的实例,这样就不会调用__init__方法
1 | class A(object): |
可以看到,这里的__new__方法会调用父类__new__方法,实际返回还是一个本身的实例,所以会正常调用__init__方法,结果如下
1 | new |
如果__new__方法不返回本身的实例,则不会去调用自身的__init__方法
1 | class A(object): |
最近被问到如何在Linux环境下对文件进行批量重命名,仔细想了一下,好像平时也没关注过这个的写法,之前有过类似需求时,作为一个Python开发者,更多地会想到直接用写Python脚本去处理,虽然知道可能可以通过shell脚本或者有直接的Linux命令去做,但一直没试过,决定写这篇文章整理下
1 | cat /proc/version |
Linux version 4.13.0-45-generic (buildd@lgw01-amd64-011) (gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.9)) #50~16.04.1-Ubuntu SMP Wed May 30 11:
针对这个问题,根据以往经验,以及网上搜索相关信息,和自己试验,大概可以通过Linux命令、shell脚本、Python脚本来解决
more >>1 | cat /proc/version |
在测试环境中,升级组件时,误把CUDA通过命令进行了升级,但由于cuda版本与cudnn版本不匹配,结果导致nvidia-smi命令报错,基于TensorFlow Serving的GPU图像识别推理也无法正常进行,于是做了些尝试终于将两者匹配,此时CUDA版本已经升级至11.0,经过测试意外地发现,此前的图像识别速度竟然提升了好几倍,猜测可能是CUDA相关升级导致的识别速度提升,但与算法同事和leader沟通没有结论后,我决定在新的测试机器上正式升级CUDA版本并验证是否速度会有提升
1 | cat /proc/version |
1 | tensorflow_model_server -version |
1 | locale |
为了方便tensorflow serving的部署,我将tensorflow serving的配置信息以超级笔记模式下「代码块」暂时存在了Mac版印象笔记(Evernote)中,当我从笔记中直接复制内容并通过vim粘贴到tensorflow serving配置文件中时,tensorflow serving启动时报了如下错误提示
more >>
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true