1. 任务背景
Datawhale组队学习中MySQL一周学习任务,通过一周组队自主学习,快速熟悉MySQL相关基础知识,并能掌握基本的数据查询操作方式
1.1 任务内容
1 | 1.软件安装及服务器设置。 |
2. 软件安装与服务器设置
2.1 系统环境
macOS High Sierra 10.13.3
2.2 软件安装
需要先安装MySQL,我使用的是MySQL 5.7.21,由于已经安装过了,不再额外安装,大致流程如下
2.2.1 安装MySQL
打开终端,输入命令,等待安装即可,可能会有查找不到安装源等问题,因不再复现此过程,暂不考虑
1 | brew install mysql |
设置管理员密码
2.2.2 打开MySQL命令行并创建数据库
直接用sudo用户进去也可以
1 | sudo mysql |
执行
1 | SHOW DATABASES; |
可以看到现在已有的数据库,其中是自带的
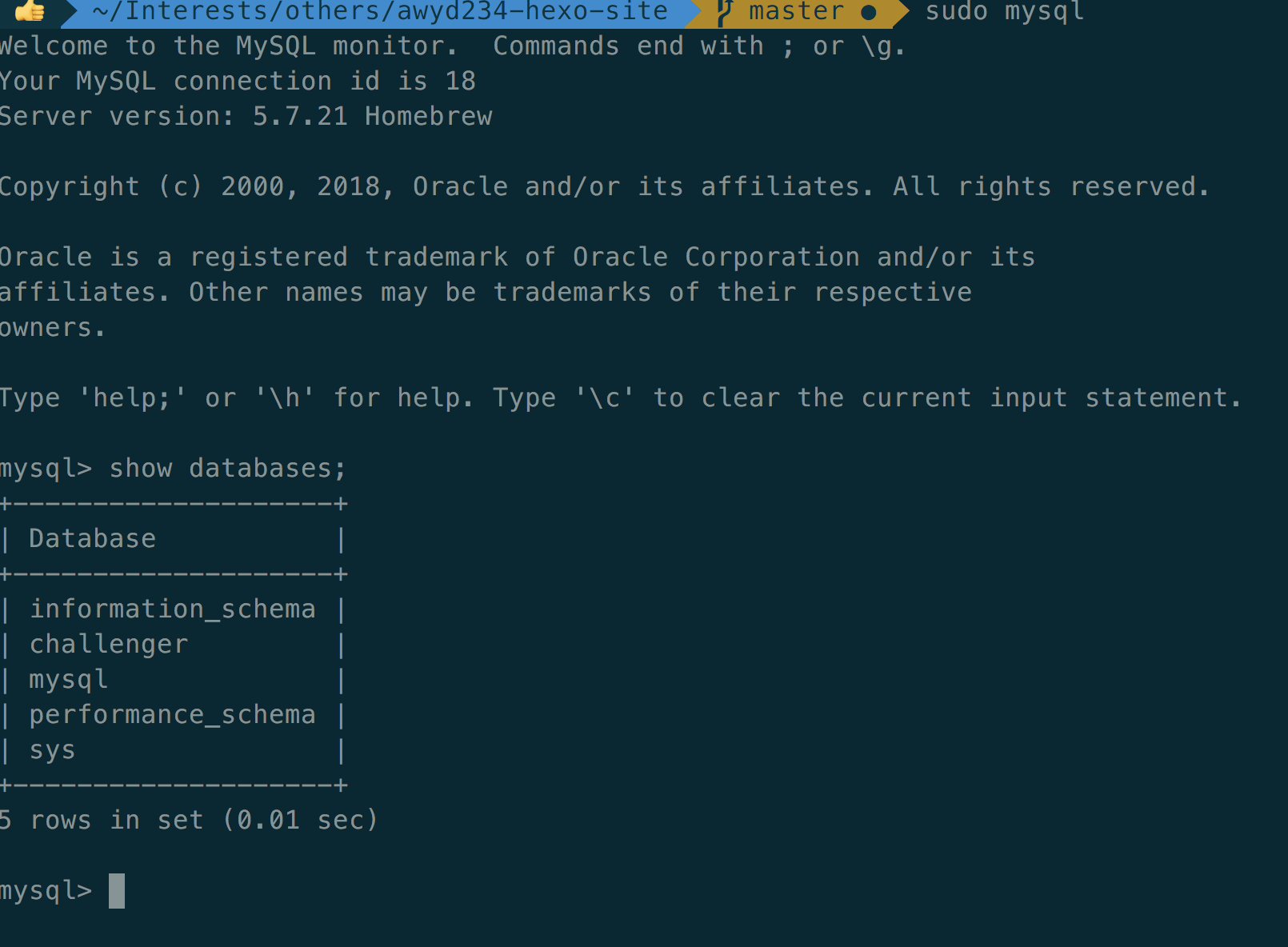
为了任务需要,我们建立一个database,取名datawhale_mysql,并使用utf8作为默认编码格式,避免后续出现编码问题
1 | CREATE DATABASE IF NOT EXISTS datawhale_mysql default character set utf8 COLLATE utf8_general_ci; |
此时我们再执行
1 | SHOW DATABASES; |
我们可以看到新创建的datawhale_mysql数据库,查看数据库创建信息
1 | SHOW CREATE DATABASE datawhale_mysql; |
可以看到
1 | mysql> SHOW CREATE DATABASE datawhale_mysql; |
2.2.3 创建用户并赋予数据库权限
实际使用数据库时,我们并不愿意使用root来管理数据库,这样会有一定风险,这时创建用户,并赋予相应的权限是一种相对安全的方式
1 | GRANT ALL PRIVILEGES ON `datawhale_mysql`.* to 'datawhale_test'@'LOCALHOST' identified by '123321'; |
为了方便起见,这里将datawhale_mysql的全权限付给了在localhost即本地的datawahle_test用户,并设置密码123321,此时会看到有警告,查看警告可以看到这种方法已经快要被废弃了,建议用新的方法,但此时还是创建成功了
1 | mysql> SHOW WARNINGS; |
2.2.4 用新用户登录数据库
在终端输入以下命令
1 | mysql -h127.0.0.1 -udatawhale_test -p |
h后为数据库所在地址,u后为用户名,p后暂不输入,此处暂不指定所使用的数据库,回车后再输入密码,即可进入,查看此时的数据库情况
1 | mysql> SHOW DATABASES; |
由于授权问题,该用户就看不到更多的数据库权限了,相应地也就没有增删改查权限,进入数据库,即可进行操作了
1 | mysql> USE datawhale_mysql; |
3. 安装可视化环境
此前工作一般直接用命令行或者公司、阿里云提供的工具来管理MySQL的,可视化工具用的比较少,毕竟用可视化工具有时候比较方便,所以还是安装了一个
3.1 安装Navicat
先前已经安装过了Navicat,而且已经过期了,不再额外安装,整体安装过程很简单,官网下载程序安装试用即可
3.2 安装DataGrip
DataGrip是JetBrains公司出的数据库管理软件,个人挺喜欢使用JetBrains家出的软件,包括Python开发使用的Pycharm,Java开发使用的IntelliJ IDEA,PHP开发使用的PhpStorm,前端开发使用的WebStorm,都很优秀,而且也有破解方法(很想支持正版,看到全家桶的价格暂时望而却步了)
3.2.1 下载安装DataGrip
在DataGrip官网下载2018.3.3版本,安装程序一共306MB,文件名为datagrip-2018.3.3.dmg,下载完后打开安装程序,将DataGrip.app拖拽到Applications即可,打开程序,本地电脑上没安装过这个,也没有配置文件,直接选Do not import settings,破解方式可以参考lanyus,需要配置hosts
1 | sudo vim /etc/hosts |
添加以下内容即可
1 | 0.0.0.0 account.jetbrains.com |
然后获取激活码,选择Activation code,粘贴进去即可
很惭愧,但暂时只能先这样了: (
3.2.2 添加数据源
不得不说,DataGrip做的还是很强大的,很多类型的数据库都支持,包括SQLite、PostgreSQL、Oracle、Microsoft SQL Server都支持,根据任务需要,直接选择MySQL即可
这时可能会发现,提示缺少驱动文件,点击安装即可

上面的数据是乱填的,这时我们使用之前创建的用户和密码,并指定数据库名称,点击Test Connection
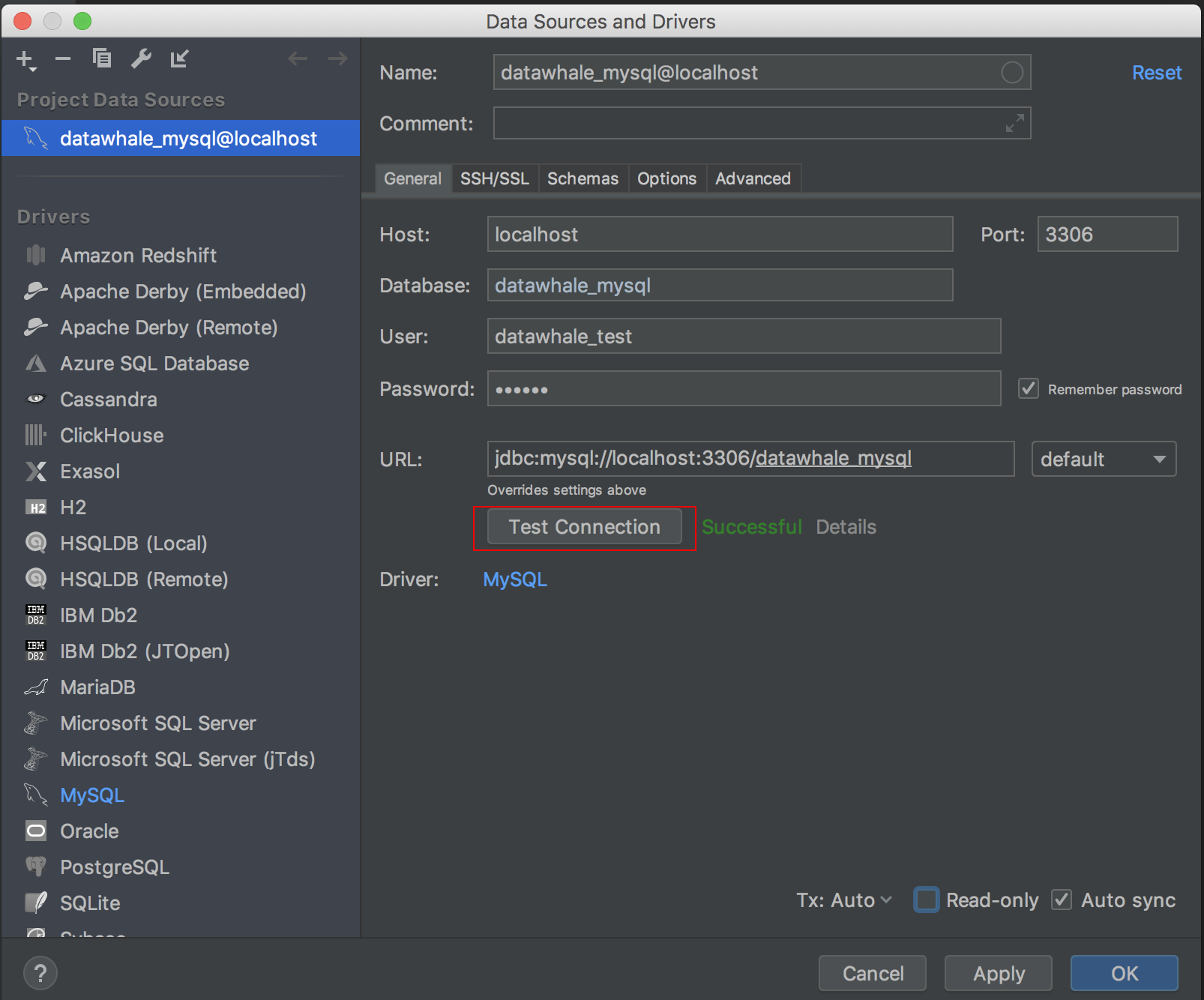
提示Successful,说明数据源配置成功,点击ok,即可看到已经添加的数据源
3.2.3 可视化创建Table
单击该数据源,选择显示all schemas
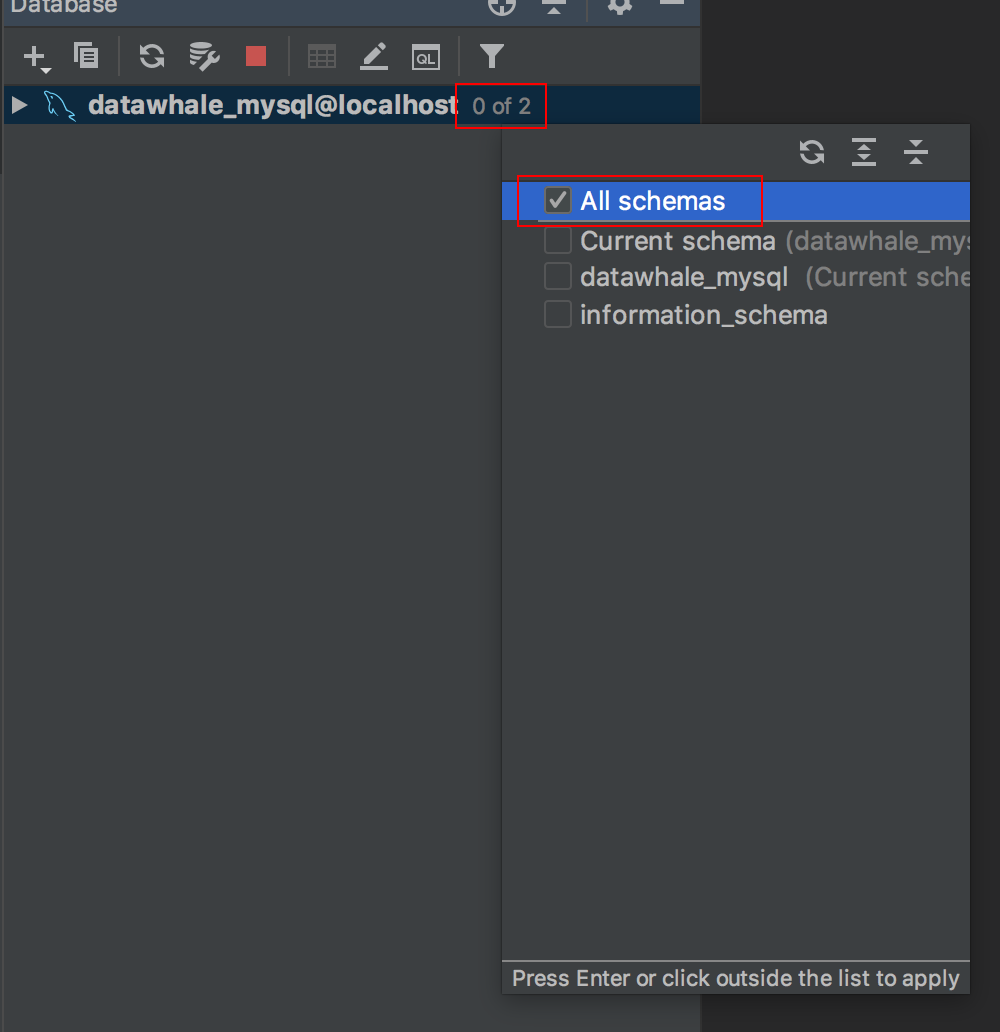
右键schemas中的数据库同名schema
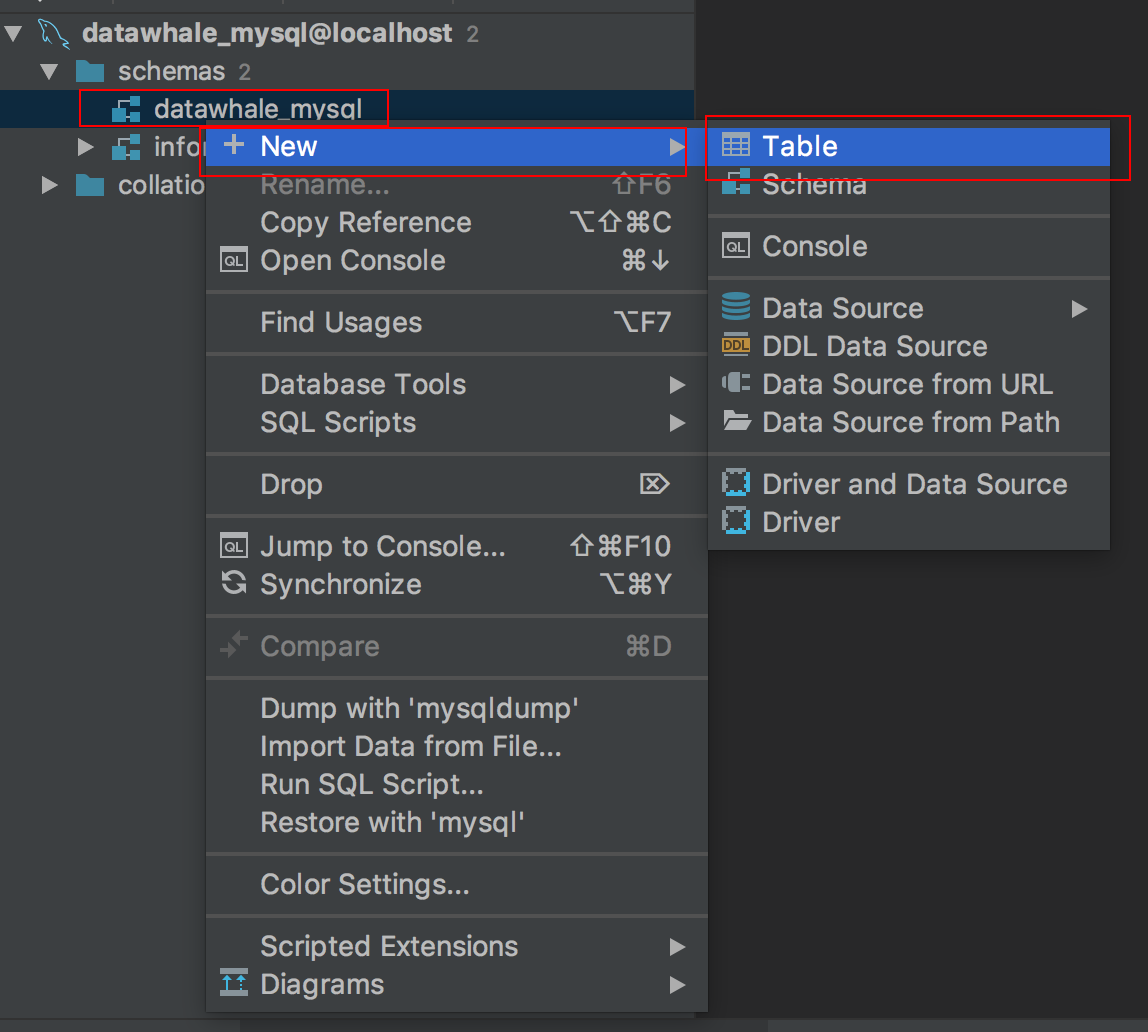
即可创建table
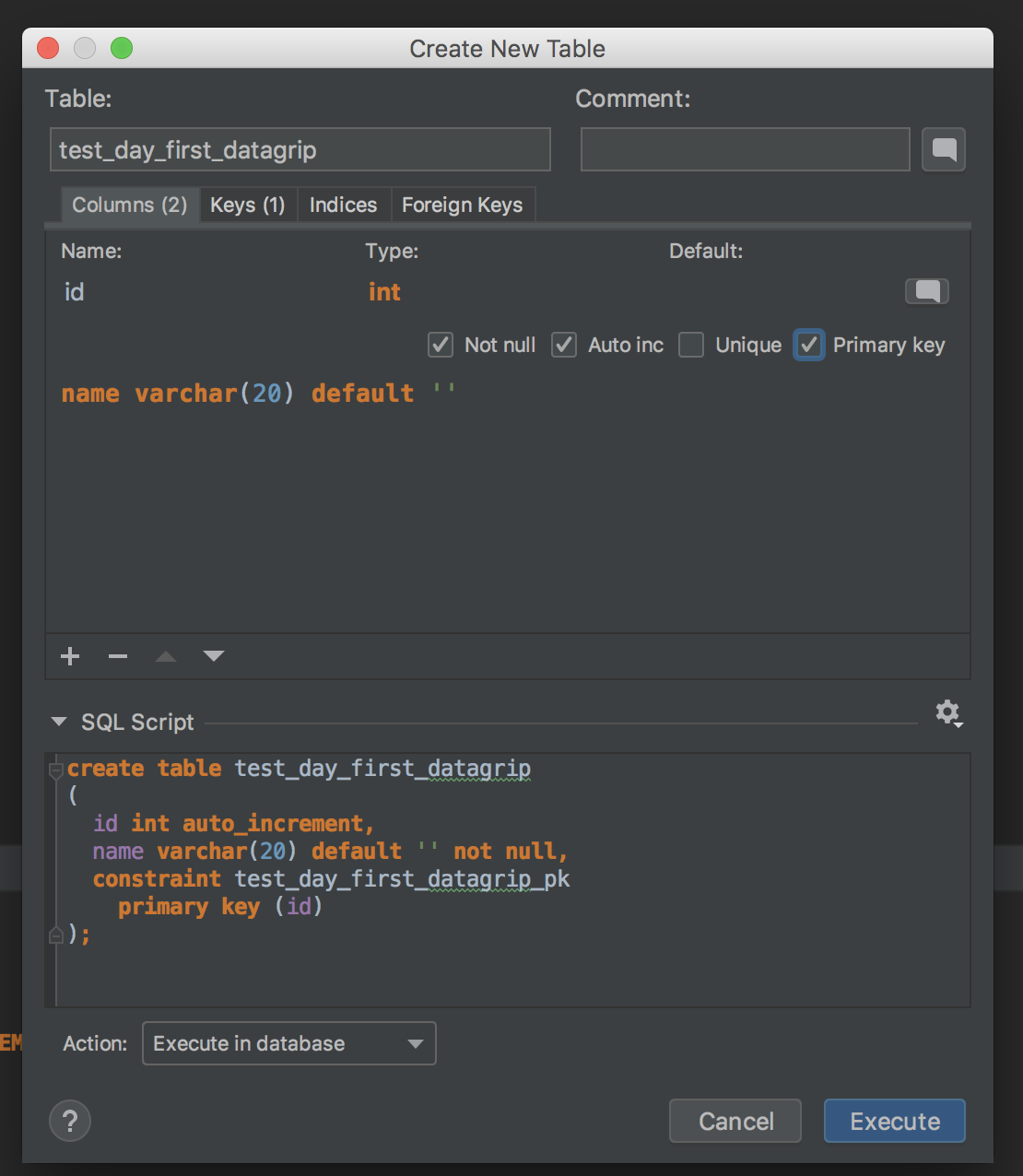
此处创建了一个名为test_day_first_datagrip的table,根据习惯,添加字段id,int类型,作为主键,并设置默认auto_increment,添加name,使用20长度的varchar类型,不可为空,并可在下方看到执行语句的预览,点击执行后,我们便可以看到已经创建完毕的table
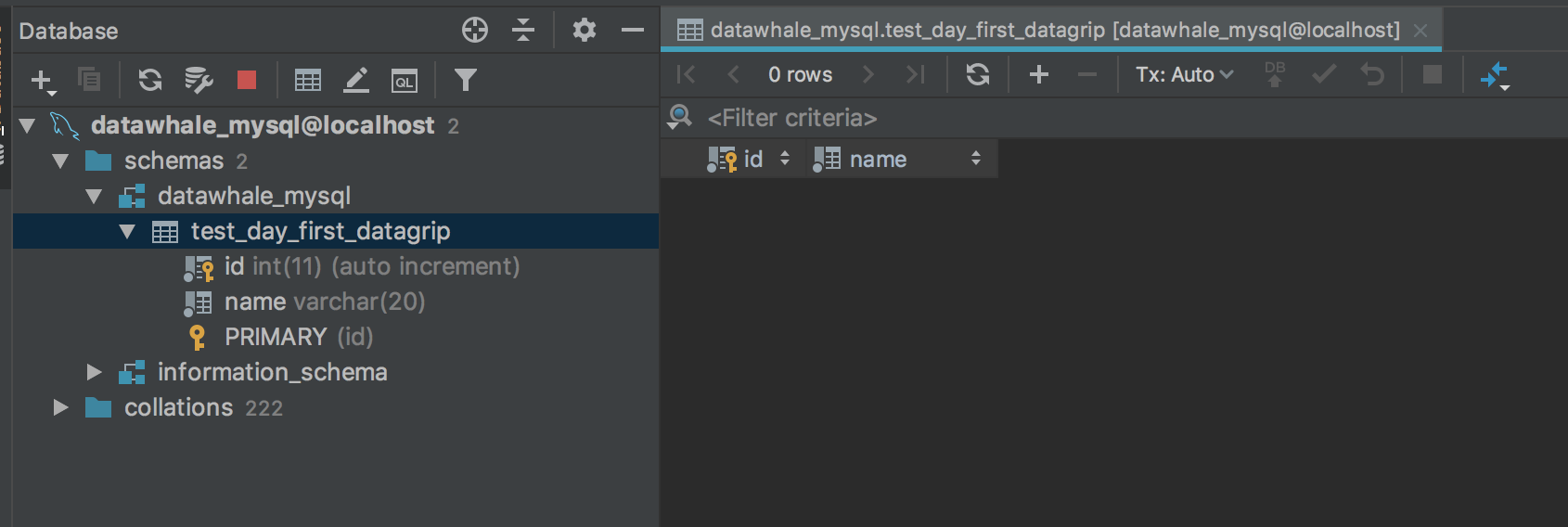
此时在终端命令行中可以看到已经创建的table,并可查看table的创建信息
1 | mysql> SHOW TABLES; |
4. 数据库的基本知识
4.1 数据库(database)定义
根据《SQL必知必会(第4版)》,数据库是一个以某种有组织的方式存储的数据集合,是保存有组织的数据的容器(通常是一个文件或一组文件),数据库软件应称为数据库管理系统(DBMS),数据库是通过 DBMS创建和操纵的容器,而具体它究竟是什么,形式如何,各种数据库都不一样。
4.2 关系型数据库
4.2.1 关系型数据库

关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织 优点:
- 易于维护:都是使用表结构,格式一致;
- 使用方便:SQL语言通用,可用于复杂查询;
- 复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。
缺点:
- 读写性能比较差,尤其是海量数据的高效率读写;
- 固定的表结构,灵活度稍欠;
4.2.2 非关系型数据库

非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。 优点:
- 格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
- 速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
- 高扩展性;
- 成本低:nosql数据库部署简单,基本都是开源软件。
缺点:
- 不提供sql支持,学习和使用成本较高;
- 无事务处理;
- 数据结构相对复杂,复杂查询方面稍欠。
非关系型数据库的分类和比较:
- 文档型
- key-value型
- 列式数据库
4.3 二维表(table)
表(table)是一种结构化的文件,可用来存储某种特定类型的数据,是某种特定类型数据的结构化清单。
数据库中的每个表都有一个名字来标识自己。这个名字是唯一的,即数据库中没有其他表具有相同的名字,但在不同的数据库下表名是可以相同的。
表具有一些特性,这些特性定义了数据在表中如何存储,包含存储什么样的数据,数据如何分解,各部分信息如何命名等信息。描述表的这组信息就是所谓的模式(schema),模式可以用来描述数据库中特定的表,也可以用来描述整个数据库(和其中表的关系)。
4.4 行(row)
表中的数据是按行存储的,所保存的每个记录存储在自己的行内,是表中的一个记录。
4.5 列(column)
表中的一个字段,所有表都是由一个或多个列组成的。
数据库中每个列都有相应的数据类型(datatype),数据类型定义了列可以存储哪些数据种类,是所允许的数据的类型,每个表列都有相应的数据类型,它限制(或允许)该列中存储的数据。数据类型还帮助正确地分类数据,并在优化磁盘使用方面起重要的作用。数据类型及其名称是 SQL不兼容的一个主要原因。
4.6 主键(primary key)
表中每一行都应该有一列(或几列)可以唯一标识自己。一列(或一组列),其值能够唯一标识表中每一行。唯一标识表中每行的这个列(或这几列)称为主键,主键用来表示一个特定的行。没有主键,更新或删除表中特定行就极为困难。
表中的任何列都可以作为主键,只要它满足以下条件:
- 任意两行都不具有相同的主键值;
- 每一行都必须具有一个主键值(主键列不允许 NULL值);
- 主键列中的值不允许修改或更新;
- 主键值不能重用(如果某行从表中删除,它的主键不能赋给以后的新行)。
在使用多列作为主键时,上述条件必须应用到所有列,所有列值的组合必须是唯一的(但单个列的值可以不唯一)。
4.7 外键
把所有数据都存放于一张表的弊端
- 表的组织结构复杂不清晰
- 浪费空间
- 扩展性极差
为了解决上述的问题,就需要用多张表来存放数据。表与表的记录之间存在着三种关系:一对多、多对多、一对一的关系。处理表之间关系问题就会利用到FOREIGN KEY
5. MySQL数据库管理系统
5.1 数据库
数据库管理系统(DataBase-Management System, DBMS)由一个互相关联的数据的集合和一组用以访问这些数据的程序组成,这个数据集合通常称为数据库(database),DBMS的主要目标就是要提供一种可以方便、高效地存储数据库信息的途径
5.2 数据表
关系模型是基于记录的模型的一个实例,基于记录的模型,之所以有此称谓,是因为数据库的结构是几种固定形式的记录,每个表都包含一种特定类型的记录,每种记录类型定义固定数目的字段或属性,表的列对应记录类型的属性
5.3 数据视图
数据库系统是一些互相关联的数据以及一组使得用户可以访问和修改这些数据的程序的集合,数据库系统的一个主要目的是给用户提供数据的抽象视图,也就是说,系统隐藏关于数据存储和维护的某些细节
5.3.1 数据抽象
一个可以用的系统必须能高效地检索数据,系统开发人员通过几个层次上的抽象来对用户屏蔽复杂性,以简化用户与系统的交互,
- 物理层(physical level),最低层次的抽象,描述数据实际上是怎样存储的,物理层详细描述复杂的底层数据结构
- 逻辑层(logical level),比物理层层次稍高的抽象,描述数据库中存储什么数据以及这些数据之间存在什么关系,虽然逻辑层的简单结构可能涉及复杂的物理层结构,但逻辑层的用户不必知道这样的复杂性,这称作物理数据独立性(physical data independence)。数据库管理员使用抽象的逻辑层,他必须确定数据库中应该保存哪些信息
- 视图层(view level),最高层次的抽象,只描述整个数据库的某个部分,数据库系统的很多用户并不需要关心所有的信息,而只需要访问数据库的一部分,视图层抽象的定义正式为了使这样的用户与系统的交互更简单,系统可以为同一数据库提供多个视图
5.3.2 实例和模型
特定时刻存储在数据库中的信息的集合称为数据库的一个实例(instance),而数据库的总体设计称为数据库模式(schema),数据库模式即使发生变化,也不频繁
5.3.3 数据模型
数据库结构的基础是数据模型(data model),数据模型是一个描述数据、数据联系、数据语义以及一致性约束的概念工具的集合,数据模型提供了一种描述物理层、逻辑层以及视图层数据库设计的方式,数据模型可划分为四类
- 关系模型(relational model),关系模型用表的集合来表示数据与数据之间的关系,每个表有多个列,没列有唯一的列名,关系模型是基于记录的模型的一种,基于记录的模型的名称的由来是因为数据库是由若干种固定格式的记录来构成的,每个表包含某种特定类型的记录,每个记录定义了固定数目的字段(或属性),表的列对应于记录类型的属性,关系数据模型是使用最广泛的数据模型,当今大量的数据库系统都是基于这种关系模型
- 实体-联系模型(entity-relationship model),实体-联系(E-R)数据模型基于对现实世界的这样一种认识:现实世界是由一组称为实体的基本对象以及这些对象间的联系构成,实体是现实世界中可区别于其他对象的一件“事情”或者一个“物体”,实体-联系模型被广泛用于数据库设计
- 基于对象的数据模型(object-based data model),面向对象的数据模型可以看成是E-R模型增加了封装、方法(函数)和对象标识等概念后的扩展,对象-关系数据模型结合了面向对象的数据模型和关系模型的特征
- 半结构化数据模型(semistructured data model),半结构化数据模型允许那些相同类型的数据项含有不同的属性集的数据定义,可扩展标记语言(eXtensible Markup Language,XML)被广泛地用来表示半结构化数据
5.3.4 SQL中的视图
视图是虚拟的表,与包含数据的表不一样,视图只包含使用时动态检索数据的查询
- Microsoft Access不支持视图,没有与 SQL视图一致的工作方式
- MySQL从版本 5起开始支持视图
- SQLite仅支持只读视图,所以视图可以创建,可以读,但其内容不能更改
作为视图,它不包含任何列或数据,包含的是一个查询
视图的常见应用
- 重用 SQL语句
- 简化复杂的 SQL操作。在编写查询后,可以方便地重用它而不必知道其基本查询细节
- 使用表的一部分而不是整个表
- 保护数据。可以授予用户访问表的特定部分的权限,而不是整个表的访问权限
- 更改数据格式和表示,视图可返回与底层表的表示和格式不同的数据
创建视图之后,可以用与表基本相同的方式使用它们。可以对视图执行SELECT操作,过滤和排序数据,将视图联结到其他视图或表,甚至添加和更新数据
视图的常见规则和限制
- 与表一样,视图必须唯一命名(不能给视图取与别的视图或表相同的名字)
- 对于可以创建的视图数目没有限制
- 创建视图,必须具有足够的访问权限。这些权限通常由数据库管理人员授予
- 视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造视图。所允许的嵌套层数在不同的 DBMS中有所不同(嵌套视图可能会严重降低查询的性能,因此在产品环境中使用之前,应该对其进行全面测试)
- 许多 DBMS禁止在视图查询中使用ORDER BY子句
- 有些 DBMS要求对返回的所有列进行命名,如果列是计算字段,则需要使用别名
- 视图不能索引,也不能有关联的触发器或默认值
- 有些 DBMS把视图作为只读的查询,这表示可以从视图检索数据,但不能将数据写回底层表。详情请参阅具体的 DBMS文档
- 有些 DBMS允许创建这样的视图,它不能进行导致行不再属于视图的插入或更新。例如有一个视图,只检索带有电子邮件地址的顾客。如果更新某个顾客,删除他的电子邮件地址,将使该顾客不再属于视图。这是默认行为,而且是允许的,但有的 DBMS可能会防止这种情况发生
5.4 存储过程
存储过程就是为以后使用而保存的一条或多条 SQL语句。可将其视为批文件,虽然它们的作用不仅限于批处理
通过把处理封装在一个易用的单元中,可以简化复杂的操作(如前面例子所述)
- 由于不要求反复建立一系列处理步骤,因而保证了数据的一致性。如果所有开发人员和应用程序都使用同一存储过程,则所使用的代码都是相同的,这一点的延伸就是防止错误。需要执行的步骤越多,出错的可能性就越大。防止错误保证了数据的一致性
- 简化对变动的管理。如果表名、列名或业务逻辑(或别的内容)有变化,那么只需要更改存储过程的代码。使用它的人员甚至不需要知道这些变化。这一点的延伸就是安全性。通过存储过程限制对基础数据的访问,减少了数据讹误(无意识的或别的原因所导致的数据讹误)的机会
- 因为存储过程通常以编译过的形式存储,所以 DBMS处理命令所需的工作量少,提高了性能
- 存在一些只能用在单个请求中的 SQL元素和特性,存储过程可以使用它们来编写功能更强更灵活的代码
缺陷
- 不同 DBMS中的存储过程语法有所不同。事实上,编写真正的可移植存储过程几乎是不可能的。不过,存储过程的自我调用(名字以及数据如何传递)可以相对保持可移植。因此,如果需要移植到别的 DBMS,至少客户端应用代码不需要变动
- 一般来说,编写存储过程比编写基本 SQL语句复杂,需要更高的技能,更丰富的经验。因此,许多数据库管理员把限制存储过程的创建作为安全措施(主要受上一条缺陷的影响)
6. 参考资料
- SQL必知必会(第4版),Ben Forta著,人民邮电出版社
- 数据库系统概念(第6版),(美)Abraham Silberschatz / (美)Henry F.Korth/ (美)S.Sudarshan,机械工业出版社
- 常见的关系型数据库和非关系型数据及其区别 - CSDN
- 外键 - CSDN