1. 用Pythonic的方式来思考
0. 前言
1 | import this |
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than right now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
1. 确认自己所用的Python版本
1 | python3 --version |
或者
1 | import sys |
Python社区已将开发重点放在了Python 3上,因此后续开发项目时,应优先考虑使用Python 3
2. 遵循PEP 8 风格指南
PEP 8全称为《 Python Enhancement Proposal #8 》
- 空白
- 使用space(空格)来表示缩进,tab(制表符)也设定为4个空格替代
- 每行字符数不要超过79
- 对于占用多行的长表达式,除首行外其余各行应在通常缩进级别上再加4个空格
- 函数与类之间用2个空行隔开,同一类中的各方法用1个空行
- 使用下标来获取列表元素、调用函数或给关键字参数赋值时不要在两旁加空格
- 变量赋值时,赋值符号左右侧应该各加上一个空格
- 命名
- 变量及属性用用小写字母来写,单词间用下划线连接,不要使用驼峰命名
- 受保护的实例属性,以单个下划线开头
- 私有的实例属性,以双下划线开头
- 类与异常各单词首字母大写
- 模块级别的常量,全部以大写字母,各单词间用下划线相连
- self通常作为实例方法的第一个参数,表示该类自身
- cls通常作为类方法的第一个参数,用于表示该对象自身
- 表达式和语句
- 检测somelist长度是否为空时,用 if not somelist 来判断
- import语句应放在文件开头,按照标准库模块、第三方模块、自用模块的顺序来import,三种之间间隔一行
- 引入模块时使用绝对名称,一定要用相对名称时,用from .bar Import foo的方式
3. 了解bytes、str与unicode的区别
- Python 3有两种表示字符序列的类型,bytes和str,bytes为原始的8位值,str为Unicode字符
- Python 2也两种表示字符序列的类型,str和unicode,str为原始的8位值,unicode为Unicode字符
- 可以用encode方法将Unicode字符转换成二进制数据,用decode方法将二进制数据转换成Unicode字符
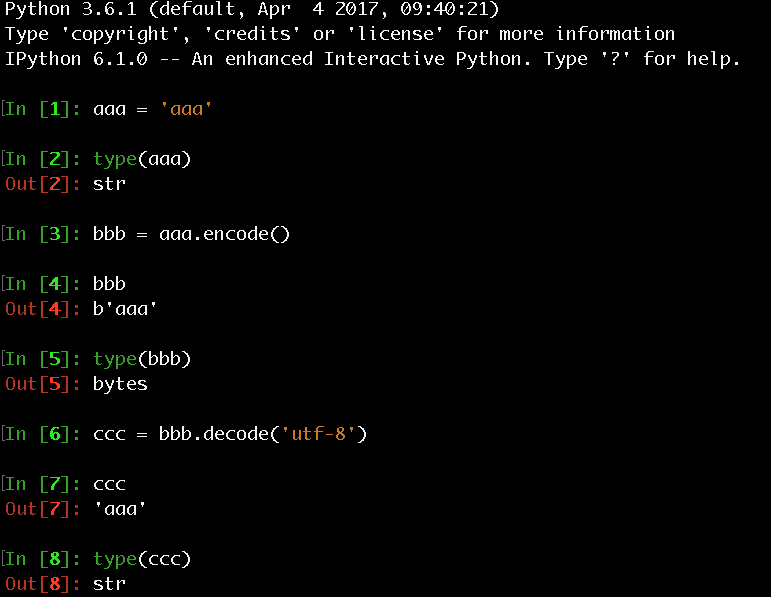
- Python 3 中, 开发者不能用 > 或 + 等操作符来混同 bytes 和 str 实例
- 从文件中读取或写入二进制数据时,应以 'rb' 或 'wb' 等二进制模式来开启文件
4. 用辅助函数来取代复杂的表达式
- 编写Python程序时,不要过度应用Pythond的语法特性,不要一味追求过于紧凑的写法,那样会写出非常复杂的表达式
- 将复杂的表达式移入辅助函数中,尤其是要反复使用的相同的逻辑
- 使用 if/else 表达式,要比用 or 或 and 这样的 Boolean操作符写成的表达式更加清晰
5. 了解切割序列的办法
- 切割操作的基本写法为 somelist[start:end],实际区间为[start, end)
- 如果从列表开头获取切片,将start留空更好,如somelist[:5]
- 如果切片一直要取到列表末尾,将end留空,如somelist[5:]
- 如果指定切片起止索引时,要从列表尾部向前算,可使用负值来表示相关偏移量,如somelist[5:-1]
- 切割列表时,即便start或者end索引越界也不会出问题,而访问列表单个元素时下标不可越界
6. 单次切片操作内,不要同时指定 start、 end 和 stride
- Python 还提供了 somelist[start:end:stride] 的写法实现步进式切割
- Python还可利用x[::-1]实现字符串反转,这种技巧只针对ASCII字符有用,对已经编码成UTF-8字符串的Unicode字符无法奏效
- 如果一定要配合start或end索引来使用stride,请考虑先做步进式切片,把切割结果赋给某个变量,然后再那个变量上做第二次切割;如果开发的程序对执行时间或内存用量的要求非常严格,以致不能使用两阶段切割法时,可以考虑内置模块itertools中的islide方法,该方法不允许start、end或slide指定负值
7. 用列表(list comprehension)推导来取代map和filter
- 列表推导要比map和filter函数清晰的多,因为其无需额外编写lambda表达式
- 字典和集也支持列表推导表达式
8. 不要使用含有两个以上表达式的列表推导
- 列表推导也支持多个if条件,处在同一循环级别中的多项条件,彼此之间默认形成and表达式
- 超过两个表达式的列表推导是很难理解的,应该尽量避免
9. 用生成器表达式来改写数据量较大的列表推导
生成器表达式(generator expression)是对列表推导和生成器的一种泛化(generalization)。生成器在表达式运行了时,并不会把整个输出序列都呈现出来,而是会估值为迭代器(iterator),这个迭代器每次可以根据生成器表达式产生一项数据。把实现列表推导的那种写法放在一堆圆括号中,就构成了生成器表达式
1 | it = (len(x) for x in open('/tmp/myfile.txt')) |
可以将生成器表达式互相组合
1 | roots = ((x, x**0.5) for x in it) |
- 生成器表达式所返回的那个迭代器是有状态的,用过一轮后,就不要反复使用了
- 输入的数据量较大时,列表推导可能会因为占用太多内存而出问题
- 串在一起的生成器表达式执行速度很快
10. 尽量使用 enumerate 取代 range
- enumerate 可以将各种迭代器包装成生成器,以便稍后产生输出值,生成器每次产生一对输出值,及循环下标和从迭代器中取得的下一个序列元素
- 尽量用 enumerate 来改写那种将range与下标访问相结合的序列遍历代码
- 可以给enumerate提供第二个参数,以指定开始计数时所用的值(默认为0)
11. 用zip函数同时遍历两个迭代器
- 如果要在 Python 2 中用zip来遍历数据量非常大的迭代器,那么应该使用itertools内置模块中的izip函数
- 内置的zip函数可以平行遍历多个迭代器,把值汇聚成tuple形式
- Python 3中的zip相当于生成器,会在遍历过程中逐次产生元祖,而Python 2中的zip则是直接把这些元祖完全生成好,并一次性地返回整份列表
- 如果提供的迭代器长度不等,zip会自动提前终止
- itertools内置模块中的zip_longest函数可以平行地遍历多个迭代器,而不用在乎它们的长度是否相等
12. 不要在 for 和 while 循环后面写 else 块
- 只有当整个循环主体都没遇到break语句时,循环后面的else块才会执行
- 不要在循环后面使用else块,因为这种写法既不直观,又容易引人误解
13. 合理利用 try/except/else/finally 结构中的每个代码块
- 如果既要将异常向上传播,又要在异常发生时执行清理工作,那就可以使用try/finally结构
- 如果try块并没有发生异常,那么就执行else块
- 如果数据不是有效的JSON格式,那么用json.loads解码时,会产生ValueError
- 无论try块是否发生异常,都可以利用try/finally复合语句中的finally块来执行清理工作
- 顺利运行try块后,若想使某些操作能在finally块的清理代码之前执行,则可将这些操作写到else块中
2. 函数
14. 尽量使用异常来表示特殊情况,而不要返回None
- 用None这个返回值来表示有特殊意义的函数,很容易使调用者犯错,因为None和0及空字符串之类的值,在条件表达式里都会评估为False
- 函数在遇到特殊情况时,应该抛出异常,而不要返回None,调用者看到该函数文档所描述的异常后,应该就可以编写相应的代码来处理他们了
15. 了解如何在闭包里使用外围作用域中的变量
- Python 支持闭包(closure):一种定义在某个作用域中的函数,这种函数引用了那个作用域里面的变量
- Python 的函数是一级对象(first-class object),我们可以直接引用函数、把函数赋给变量、把函数当作参数传给其他函数,并通过表达式及if语句对其进行比较和判断
- 在表达式中引用变量时,Python
解释器将按如下顺序遍历各作用域,以解析该引用
- 当前函数的作用域
- 任何外围作用域(例如,包含当前函数的其他函数)
- 包含当前代码的那个模块的作用域(也叫全局作用域,global scope)
- 内置作用域(也就是包含 len 及 str 等函数的那个作用域)
- 对于定义在某作用域内的闭包来说,它可以引用这些作用域中的变量
- 使用默认方式对闭包内的变量赋值,不会影响外围作用域中的同名变量
- 在 Python 3 中,程序可以在闭包内使用nonlocal语句来修饰某个名称,使该闭包能够修改外围作用域中的同名变量
- 在 Python 2 中,程序可以使用可变值(例如,包含单个元素的列表)来实现与nonlocal语句相仿的机制
- 除了那种比较简单的函数,尽量不要使用nonlocal函数
16. 考虑用生成器来改写直接返回列表的函数
- 使用生成器比把收集到的结果放入列表里返回给调用者更加清晰
- 由生成器函数所返回的那个迭代器,可以把生成器函数体中,传给yield表达式的那些值,逐次产生出来
- 无论输入量有多大,生成器都能产生一系列输出,因为这些输入量和输出量,都不会影响它在执行时所耗的内存
17. 在参数上面迭代时,要多加小心
- 函数在输入的参数上面多次迭代时要当心:如果参数是迭代器,那么可能会导致奇怪的行为并错失某些值
- Python 的迭代器协议,描述了容器和迭代器之间应该如何与iter和next内置函数、for循环及相关表达式相互配合
- 把
__iter__方法实现为生成器,即可定义自己的容器类型 - 想判断某个值是迭代器还是容器,可以拿该值为参数,两次调用iter函数比较结果是否相同
18. 用数量可变的位置参数减少视觉杂讯(visual noise)
- 在 def 语句中使用 *args,即可令函数接受数量可变的位置参数
- 调用函数时,可以采用 * 操作符,把序列中的元素当成位置参数,传给该函数
- 对生成器使用 * 操作符,可能导致程序耗尽内存并崩溃
- 在已经接受 *arg 参数的函数上面继续添加位置参数,可能会产生难以排查的 bug
19. 用关键字参数来表达可选的行为
- 关键字参数的顺序不限,只要把函数所要求的全部位置参数都指定好即可,还可以混合使用关键字参数和位置参数来调用函数;位置参数必须出现在关键字参数之前;每个参数只能指定一次
- 只使用位置参数来调用函数,可能会导致这些参数值的含义不够明确,而关键字参数则能阐明每个参数的意图
- 给函数添加新的行为时,可以使用带默认的关键字参数,以便与原有的函数调用代码保持兼容
- 可选的关键字参数,总是应该以关键字形式来指定,而不应该以位置参数的形式来指定
20. 用 None 和文档字符串来描述具有动态默认值的参数
- 参数的默认值,会在每个模块加载进来的时候求出,而很多模块都是在程序启动时加载的,注意参数中用类似when=datetime.now()的情况,对[]或{}等动态的值,这可能会导致奇怪的行为
- 在 Python 中若想正确实现动态默认值,习惯上是把默认值设为None,并在文档字符串(docstring)里面把None所对应的实际行为描述出来
- 如果参数的实际默认值是可变类型(mutable),那就一定要记得用None作为形式上的默认值
21. 用只能以关键字形式指定的参数来确保代码明确
Python 3 中可以通过参数列表中的
*号来标志位置参数的终结,之后参数只能以关键字形式来指定```python def test_function(aaa, bbb, *, ccc=True, ddd=False): print(aaa, bbb, ccc, ddd) return ccc
1
2
3
4
5
6
7
8
9
10
11
12
<div align=center>{% asset_img "21 Python3 Keyword Arguments.png"%}</div>
- 与 Python 3 不同,Python 2 并没有明确的语法来定义这种只能以关键字形式指定的参数,不过,我们可以在参数列表中使用 ** 操作符,并且令函数在遇到无效的调用时抛出TypeErrors,这样就可以实现与 Python 3 相同的功能了
- ```python
def safe_division_d(number, divisor, **kwargs):
ignore_overflow = kwargs.pop('ignore_overflow', False)
ignore_zero_div = kwargs.pop('ignore_zero_div', False)
if kwargs:
raise TypeError('Unexpected **kwargs: %r' % kwargs)
print ignore_overflow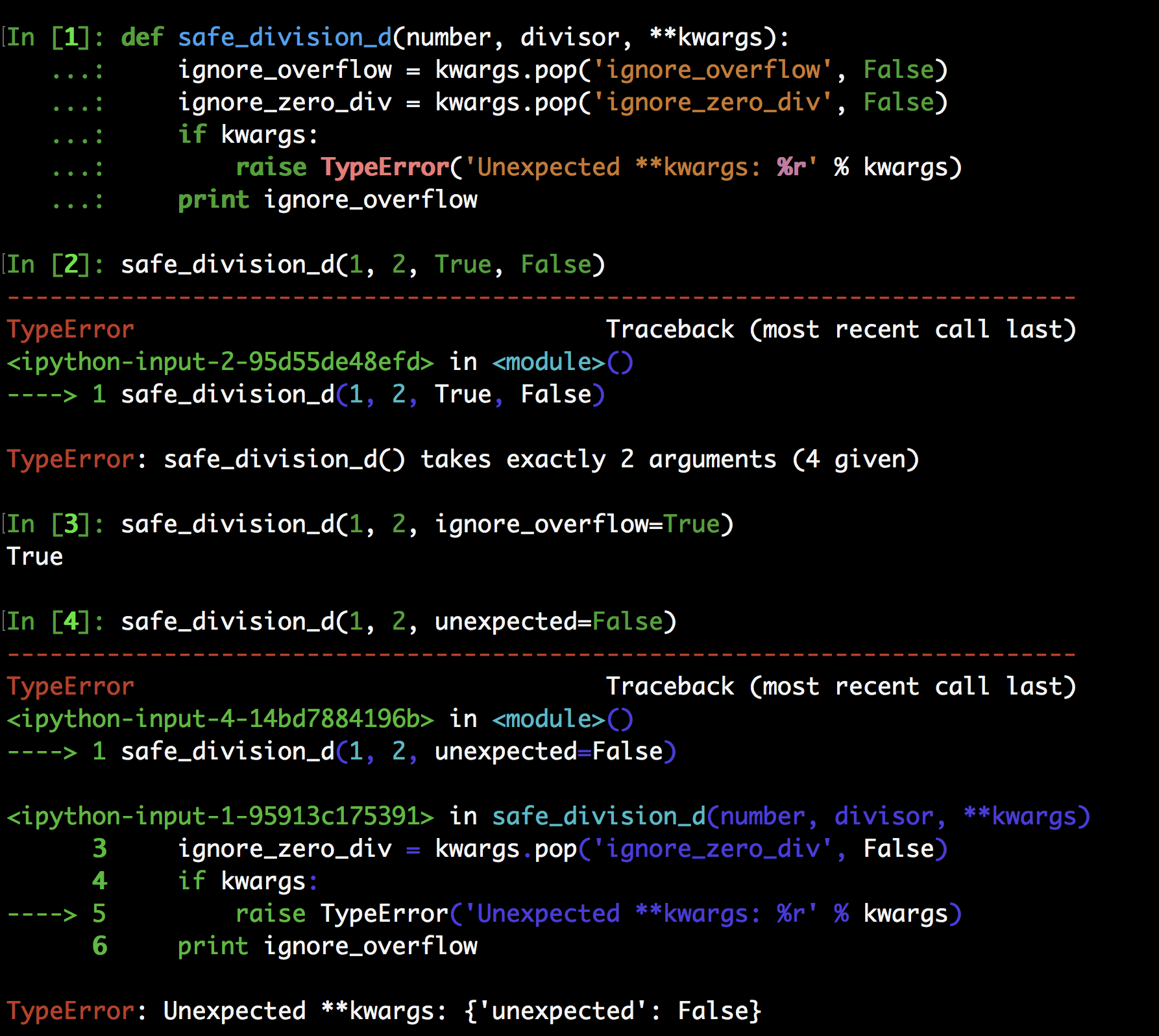
3. 类与继承
22. 尽量用辅助类来维护程序的状态,而不要用字典和元组
- 用来保存程序状态的数据结构一旦变得过于复杂,就应该将其拆解为类,以便提供更加明确的接口,并更好地封装数据,这样做也能够在接口与具体实现之间创建抽象层
- 当字典的嵌套多于一层的时候,就应该避免了
- 元组的元素一旦超过两项,就应该考虑用其它方法来实现了,可以考虑使用 collections 模块中的 namedtuple(具名元组)类型来实现
- namedtuple 类无法指定各参数的默认值,对于可选属性比较多的数据来说,namedtuple 用起来很不方便;如果没办法完全控制 namedtuple 实例的用法,那么最好是定义自己的类
- 保存内部状态的字典如果变得比较复杂,那就应该把这些代码拆解为多个辅助类
23. 简单的接口应该接受函数,而不是类的实例
- 我们可以在 Python
代码中定义名为
__call__的特殊方法,该方法使相关对象能够像函数那样得到调用 - 对于连接各种 Python 组件的简单接口来说,通常应该给其直接传入函数,而不是先定义某个类,然后再传入该类的实例
- Python 中的函数能和方法都可以像一级类那样引用,因此,它们与其他类型的对象一样,也能够放在表达式里面
- 如果要用函数来保存状态,那就应该定义新的类,并令其实现
__call__的方法,而不要定义带状态的闭包
24. 以 @clssmethod 形式的多态去通用地构建对象
- Python 中,不仅对象支持多态,类也支持多态
- 多态,使得继承体系中的多个类都能以各自所独有的方式来实现某个方法
- @classmethod 形式的多态,针对的是整个类,而不是从该类构建出的对象
- 在 Python
程序中,每个类只能有一个构造器,也就是
__init__方法,通过 @classmethod 的机制,可以用一种与构造器相仿的方式来构造类的对象 - 通过类方法多态机制,我们能够以更加通用的方式来构建并拼接具体的子类
25. 用 super 初始化父类
- 如果子类受到了多重继承的影响(实际应避免这种做法),那么直接调用超类的
__init__方法,可能会产生无法预知的行为 - 如果子类继承自两个单独的超类,而那两个超类又继承自同一个公共基类,那么久构成了钻石形继承体系,这种继承会使钻石顶部的那个公共基类多次执行其
__init__方法,从而产生意想不到的行为 - Python 2.2 增加了内置的 super 函数,并且定义了方法解析顺序(method
resolution order,MRO),MRO
以标准的流程来安排超类之间的初始化顺序(e.g.
深度优先,从左至右),它也保证钻石顶部那个公共基类的
__init__方法只会运行一次 - Python 2 中内置的super函数有两个问题值得注意
- super语句写出来有点麻烦,我们必须指定