背景介绍
环境
- 操作系统:macos 15
- go版本:go1.20
- IDE:GoLand
- 辅助:ChatGPT 4o
整体脉络
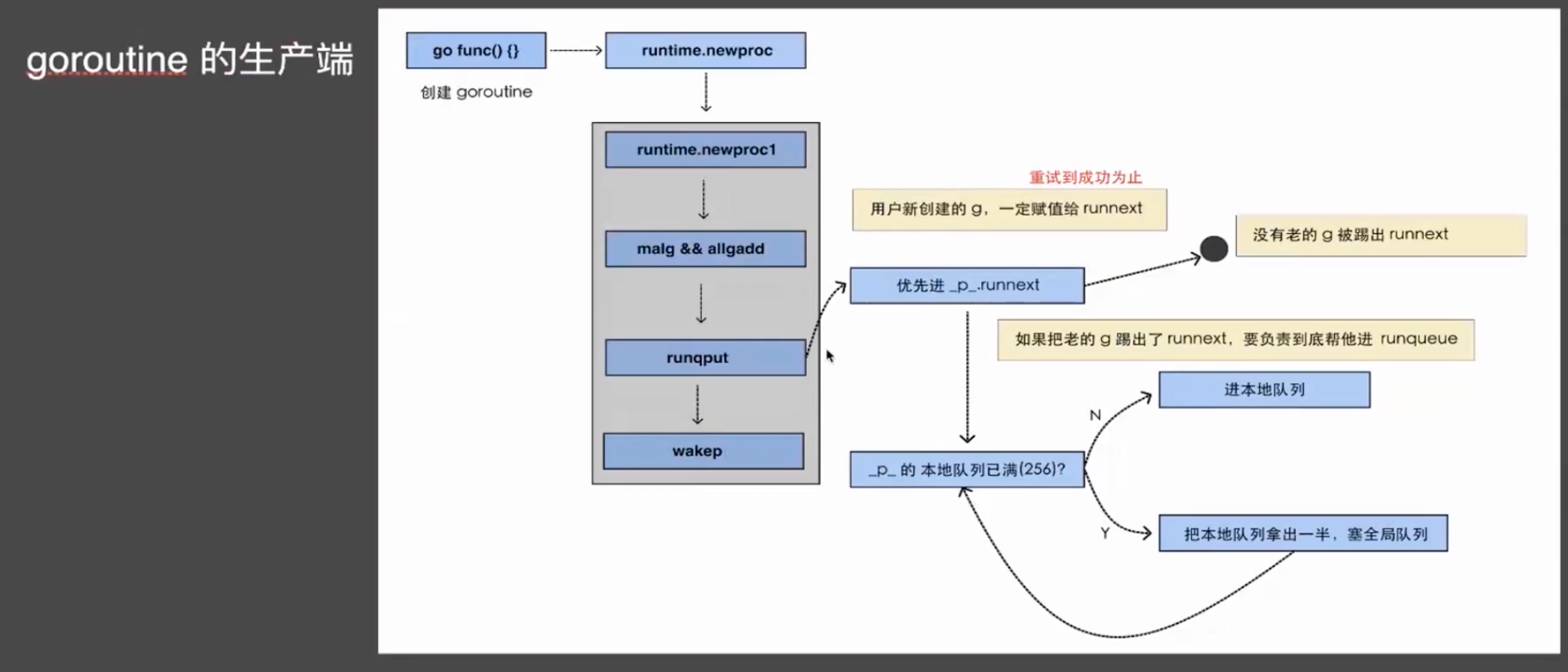
runqput
源码
位于src/runtime/proc.go
1 | // runqput tries to put g on the local runnable queue. |
randomizeScheduler
1 | if randomizeScheduler && next && fastrandn(2) == 0 { |
调度器的随机化标志,如果开启这会看fastrandn(2)生成的数据
1 | //go:nosplit |
fastrand()会生成一个uint32的随机数,具体生成算法暂不研究,将其扩展为uint32,这样右移时不会溢出,当n为2,此处相当于左移一位,然后右移,其实就是看最高位是0还是1,但看源码里randomizeScheduler默认就是false,除非修改源码,此处逻辑一般会跳过
retryNext
1 | if next { |
cas
关于pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))),关于cas
1 | //go:nosplit |
得到一个指向gp的uintptr,odl与new也被转换为uintptr类型,这里尝试将指向值由old转为new,如果值为old,则转为new并返回true,否则不改变值并返回false
!pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp)))
这里尝试将gp放入runnext,虽然前一句就是将runnext赋值给oldnext,但可能中途runnext被其他线程修改了,如果没有被修改,此处就可以顺利将gp放入runnext,且此处为true,否则为false走向retryNext即重来这一步
if oldnext == 0
如果oldnext为0,就说明此前runnext为空,即此前没有goroutine,则可以直接将gp放入runnext并结束
retry
1 | retry: |
if t-h < uint32(len(pp.runq))
检查当前队列是否已满,如果队列未满,则将gp放入队列下一个位置,此时gp就是从runnext里被挤出来的那个
if runqputslow(pp, gp, h, t)
如果队列已满,则将gp交给runqputslow处理,可能放入全局队列
runqputslow
1 | // Put g and a batch of work from local runnable queue on global queue. |
var batch [len(pp.runq)/2 + 1]*g
定义数组batch,长度为本地队列长度的一半加一
if n != uint32(len(pp.runq)/2)
检查队列是否已经被填满了
for i := uint32(0); i < n; i++
将本地队列的前n(n已经减半)个元素放入batch数组中
if !atomic.CasRel(&pp.runqhead, h, h+n)
利用CAS操作,将头部索引后移n个位置,执行失败则重来
batch[n] = gp
将gp放入batch末尾
if randomizeScheduler
如果用了调度器随机化,则将batch里的元素随机打乱
for i := uint32(0); i < n; i++
构建链表,将goroutine链接起来
globrunqputbatch(&q, int32(n+1))
把batch里的goroutine放入全局队列,共n+1个goroutine
runqget
源码
1 | // Get g from local runnable queue. |
整体分析
此处代码没那么复杂,整体简要分析吧,inheritTime表示是否继承当前时间片的剩余时间
if next != 0 && pp.runnext.cas(next, 0)
runnext中有没有goroutine,有的就返回并置为0,如果这里不为0且没法转为0,则说明被其他P偷走了,其他的P只能将runnext设置为0而不能设置非0,因此CAS失败的话没必要重试
if t == h
检查本地队列是否为空,如果为空则直接返回
gp := pp.runq[h%uint32(len(pp.runq))].ptr()
将本地队列的队首元素返回,并将队首指向下一个,获取到的goroutine不继承时间片,从新时间片开始
globrunqput
源码
1 | // Put gp on the global runnable queue. |
sched.lock锁
必须有sched.lock锁,保证线程安全,全局可运行队列是多个P共享的数据结构,可能被多个线程并发访问,为了保证数据一致性和防止竞态条件,必须在操作全局队列时持有sched.lock锁
write barriers
可能在Stop-The-World(STW)阶段运行,因此不能使用写屏障
同时指定了//go:nowritebarrierrec,编译器在这个函数及其调用的函数中不允许使用写屏障
Stop-The-World(STW)
垃圾收集等操作中,Go runtime会停止所有goroutine,即进入了STW阶段,STW阶段运行的代码不能使用写屏障,因为写屏障会修改对象的状态,而在STW阶段对象的状态不能被修改
写屏障
写屏障(Write Barrier)是一种内存管理技术,主要用于GC来维护堆对象的正确性和一致性,GC中,写屏障确保在对象引用被修改时,GC能正确地跟踪这些修改,以便进行有效的内存回收,写屏障的作用是维护GC的准确性,特别是在并发GC和增量GC中
基本概念
- 维护引用关系
- 当一个对象引用发生变化时,写屏障记录这些变化,确保GC能正确地识别和处理被修改的引用
- 辅助垃圾回收
- 写屏障帮助GC维护堆对象的准确状态,避免在垃圾回收过充值丢失引用,从而防止误回收活跃对象
类型
- 插入式写屏障(Insertion Write Barrier)
- 在写入新引用时触发。
- 删除式写屏障(Deletion Write Barrier)
- 在删除引用时触发。
- 混合式写屏障(Mixed Write Barrier)
- 结合了插入和删除的功能。
Go中的作用
Go的GC使用写屏障来支持并发标记-清除算法,写屏障在Go的GC中起到了关键作用,特别是在垃圾收集器和应用程序同时运行的情况下,Go 使用的主要是混合写屏障
- 增量更新(Incremental Update):
- 在写入新引用时,写屏障记录新引用对象,使得垃圾收集器能够正确地标记新的引用
- 静态屏障(Static Barrier):
- 在编译时插入写屏障代码,确保所有的指针写操作都经过写屏障
sched.runq.pushBack(gp)
将goroutine放入全局队列的队尾,需要区分pp.runq
| Items | pp.runq | sched.runq |
|---|---|---|
| 定义 | 每个处理器(P)独有的本地可运行队列 | 全局可运行队列,所有P共用 |
| 作用 | P运行时,会首先从pp.runq中获取待执行的goroutine | 存储无法立即分配给某个P的goroutine |
| 特点 | 高效性:本地队列,访问速度快,减少了全局锁竞争,提升了调度器性能 | 负载均衡:某个P本地队列为空时,可以从sched.runq中获取goroutine来保持负载均衡 |
| 结构 | 循环队列,通过runqhead和runqtail指针运行 | 全局队列,需要加锁sched.lock保证线程安全 |
globrunqget
源码
1 | // Try get a batch of G's from the global runnable queue. |
n := sched.runqsize/gomaxprocs + 1
计算每个P平均可获取的goroutine数量,加一为了保证至少一个
如果这个数值大于了全局队列中的goroutine数量,则调整为该值,如果设置了max且大于0,调整为max
确保n不会超过本地队列的一半
gp := sched.runq.pop()
获取全局队列中第一个goroutine,将这n个goroutine放入P的本地队列
对比runqputslow
runqputslow会在本地队列满时放一半到全局队列,globrunqget会在P的本地队列为空或者即将为空时放入,因此是不冲突的,不会反复来回倒腾