背景介绍
由Datawhale组织的「一周算法实践」活动,通过短期实践一个比较完整的数据挖掘项目,迅速了解相关实际过程
GitHub Link
GitHub - Datawhale Datamining Practice - awyd234
任务描述
【任务3 - 模型调优】使用网格搜索法对7个模型进行调优(调参时采用五折交叉验证的方式),并进行模型评估,记得展示代码的运行结果~
代码实现
此处需要用到sklearn中的GridSearchCV
1 | from sklearn.model_selection import GridSearchCV |
修改fit_and_evaluate_model函数,将model修改为带入参数的GridSearchCV
1 | clf = model.fit(x_train_standard, y_train.ravel()) |
1. 逻辑回归
对逻辑回归,重要的参数就是C了,于是设置
1 | lr = LogisticRegression(random_state=2018) |
此处以roc_auc作为评价指标,可以得出最佳参数为
1 | 'C': 1.5 |
对应最佳结果0.7871561856456848,整体指标与原结果对比如下
| Evaluation | Train Set | Test Set | 调优后Train Set | 调优后Test Set |
|---|---|---|---|---|
| Accuracy | 0.8049293657950105 | 0.7876664330763841 | 0.8046287947099489 | 0.7834618079887876 |
| Precision | 0.7069351230425056 | 0.6609195402298851 | 0.7053571428571429 | 0.6436781609195402 |
| F1-score | 0.4933645589383294 | 0.4315196998123827 | 0.49297971918876754 | 0.4202626641651032 |
| Recall | 0.37889688249400477 | 0.3203342618384401 | 0.37889688249400477 | 0.31197771587743733 |
| Auc | 0.8198240444948494 | 0.7657454644090431 | 0.8198976318343639 | 0.7653151179410139 |
ROC曲线如图
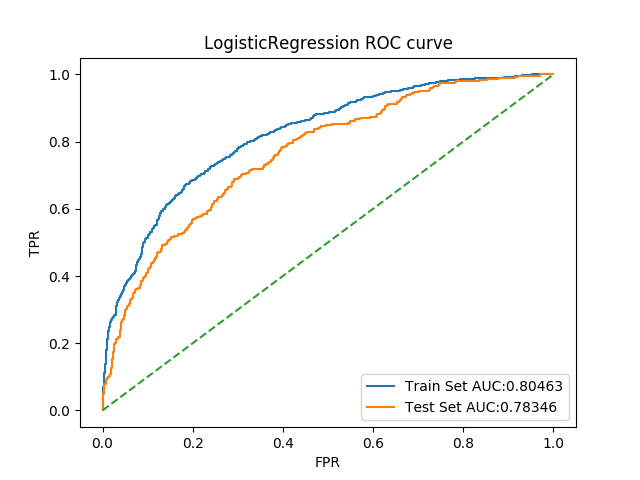
2. SVM
对SVM,重要的参数就是C了,于是设置
1 | svm_clf = SVC(random_state=2018, probability=True) |
此处以roc_auc作为评价指标,可以得出最佳参数为
1 | 'C': 0.5 |
对应最佳结果0.7841281618583947,整体指标与原结果对比如下
| Evaluation | Train Set | Test Set | 调优后Train Set | 调优后Test Set |
|---|---|---|---|---|
| Accuracy | 0.8428013225127743 | 0.7806587245970568 | 0.8091373609858732 | 0.7729502452697968 |
| Precision | 0.9146666666666666 | 0.7017543859649122 | 0.902834008097166 | 0.7108433734939759 |
| F1-score | 0.5674110835401158 | 0.3382663847780127 | 0.4125809435707678 | 0.2669683257918552 |
| Recall | 0.41127098321342925 | 0.22284122562674094 | 0.2673860911270983 | 0.16434540389972144 |
| Auc | 0.9217853154299663 | 0.7531297924947575 | 0.8959883837815428 | 0.7626887004058298 |
ROC曲线如图
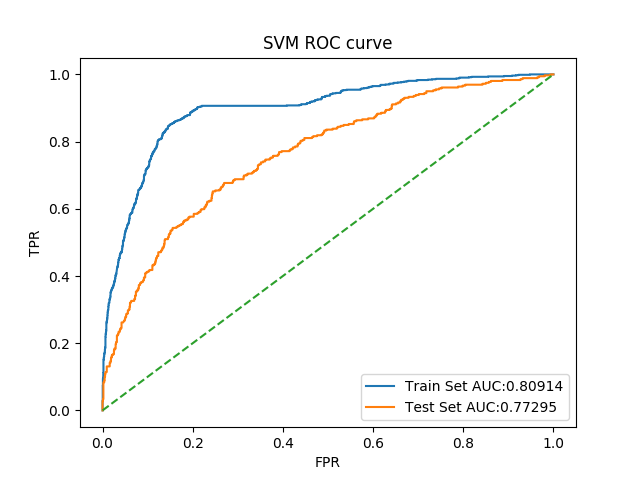
3. 决策树
对于决策树而言,重要的参数就是max_depth和max_features了
1 | dt_clf = tree.DecisionTreeClassifier(random_state=2018) |
此处以roc_auc作为评价指标,可以得出最佳参数为
1 | 'max_depth': 4, 'max_features': 0.6 |
对应最佳结果0.7375807248945857,整体指标与原结果对比如下
| Evaluation | Train Set | Test Set | 调优后Train Set | 调优后Test Set |
|---|---|---|---|---|
| Accuracy | 1.0 | 0.6860546601261388 | 0.7950105199879771 | 0.759635599159075 |
| Precision | 1.0 | 0.3850129198966408 | 0.6478599221789884 | 0.5363636363636364 |
| F1-score | 1.0 | 0.39946380697050937 | 0.49406528189910975 | 0.4075993091537133 |
| Recall | 1.0 | 0.415041782729805 | 0.39928057553956836 | 0.3286908077994429 |
| Auc | 1.0 | 0.5960976703911197 | 0.773979853421715 | 0.7002558605364464 |
ROC曲线如图
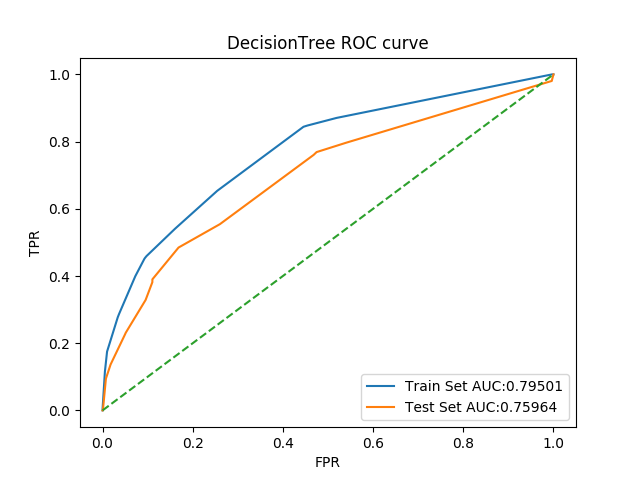
4. RandomForest
对于决策树而言,重要的参数就是max_depth和max_features了
1 | random_forest_clf = RandomForestClassifier(random_state=2018) |
此处以roc_auc作为评价指标,可以得出最佳参数为
1 | 'n_estimators': 280 |
对应最佳结果0.7831171777607903,整体指标与原结果对比如下
| Evaluation | Train Set | Test Set | 调优后Train Set | 调优后Test Set |
|---|---|---|---|---|
| Accuracy | 0.9849714457469192 | 0.7680448493342676 | 1.0 | 0.7869656622284513 |
| Precision | 1.0 | 0.5875 | 1.0 | 0.7037037037037037 |
| F1-score | 0.9690976514215082 | 0.3622350674373796 | 1.0 | 0.38461538461538464 |
| Recall | 0.9400479616306955 | 0.2618384401114206 | 1.0 | 0.2646239554317549 |
| Auc | 0.9995264919231882 | 0.7194427926095167 | 1.0 | 0.7575388876717473 |
ROC曲线如图
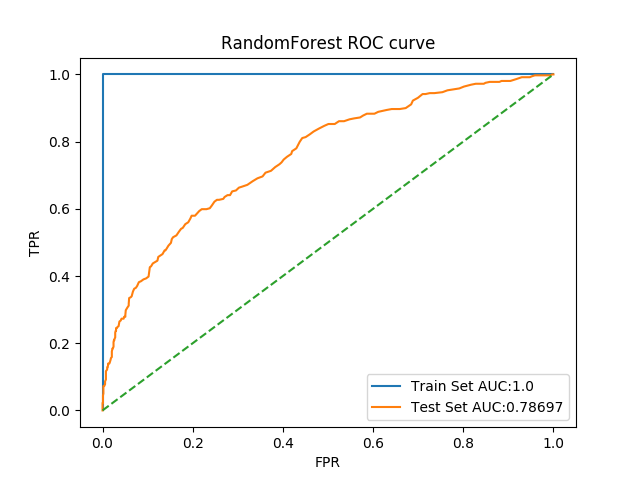
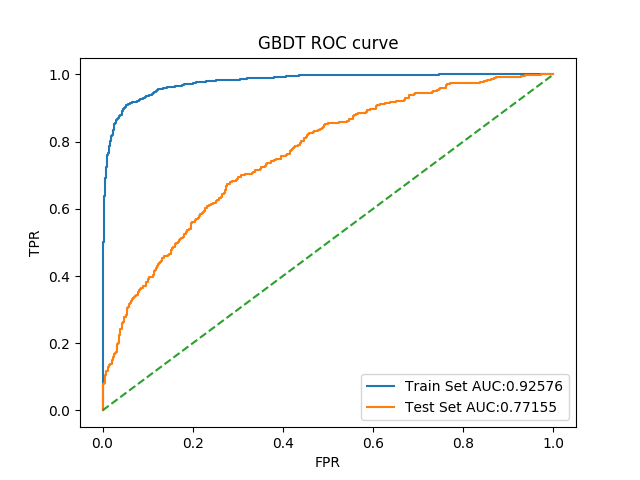
5. GBDT
对于GBDT而言,选取参数是n_estimators和subsample了
1 | gbdt_clf = GradientBoostingClassifier(random_state=2018) |
此处以roc_auc作为评价指标,可以得出最佳参数为
1 | 'n_estimators': 250, 'subsample': 0.9 |
对应最佳结果0.7838716862923119,整体指标与原结果对比如下
| Evaluation | Train Set | Test Set | 调优后Train Set | 调优后Test Set |
|---|---|---|---|---|
| Accuracy | 0.8623384430417794 | 0.7806587245970568 | 0.9257589419897806 | 0.7715487035739313 |
| Precision | 0.8836734693877552 | 0.6116504854368932 | 0.9622047244094488 | 0.5668016194331984 |
| F1-score | 0.6540785498489425 | 0.44601769911504424 | 0.831858407079646 | 0.46204620462046203 |
| Recall | 0.5191846522781774 | 0.35097493036211697 | 0.7326139088729017 | 0.38997214484679665 |
| Auc | 0.9207464353427005 | 0.7632677120173599 | 0.9781873658714425 | 0.7611890081687585 |
ROC曲线如图
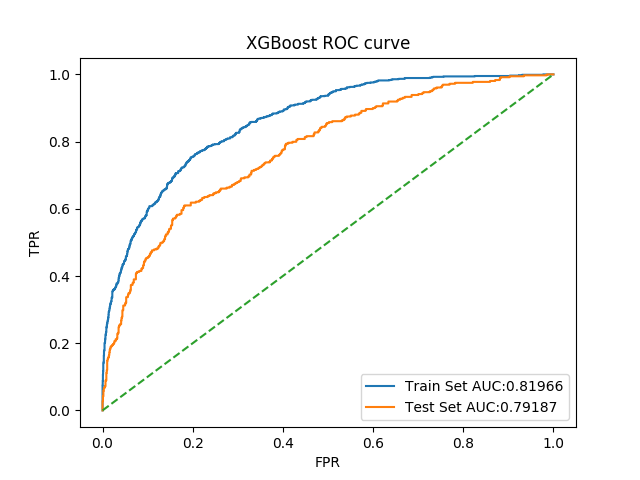
6. XGBoost
对于XGBoost而言,选取参数是max_depth和min_child_weight了
1 | xgbt_clf = XGBClassifier(random_state=2018) |
此处以roc_auc作为评价指标,可以得出最佳参数为
1 | 'max_depth': 2, 'min_child_weight': 3 |
对应最佳结果0.7994358828536744,整体指标与原结果对比如下
| Evaluation | Train Set | Test Set | 调优后Train Set | 调优后Test Set |
|---|---|---|---|---|
| Accuracy | 0.8539224526600541 | 0.7841625788367204 | 0.8196573489630298 | 0.7918710581639804 |
| Precision | 0.875 | 0.624390243902439 | 0.7853658536585366 | 0.6684782608695652 |
| F1-score | 0.6255778120184899 | 0.45390070921985815 | 0.517684887459807 | 0.4530386740331492 |
| Recall | 0.486810551558753 | 0.3565459610027855 | 0.38609112709832133 | 0.3426183844011142 |
| Auc | 0.9174710772897927 | 0.7708522424963224 | 0.8614537972510078 | 0.7757516718308242 |
ROC曲线如图
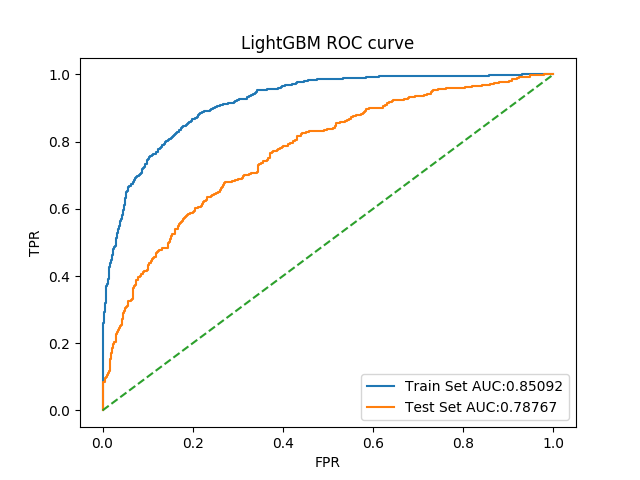
7. LightGBM
对于LightGBM而言,选取参数是max_depth和max_features
1 | light_gbm_clf = LGBMClassifier(random_state=2018) |
此处以roc_auc作为评价指标,可以得出最佳参数为
1 | 'max_depth': 3, 'num_leaves': 20 |
对应最佳结果0.7988766884324692,整体指标与原结果对比如下
| Evaluation | Train Set | Test Set | 调优后Train Set | 调优后Test Set |
|---|---|---|---|---|
| Accuracy | 0.9957920048091373 | 0.7701471618780659 | 0.8509167418094379 | 0.7876664330763841 |
| Precision | 1.0 | 0.5688888888888889 | 0.8491735537190083 | 0.6386138613861386 |
| F1-score | 0.9915356711003627 | 0.4383561643835616 | 0.6236722306525039 | 0.45989304812834225 |
| Recall | 0.9832134292565947 | 0.3565459610027855 | 0.49280575539568344 | 0.3593314763231198 |
| Auc | 0.9999826853318788 | 0.7535210165566023 | 0.9184685945587694 | 0.7689117711495729 |
ROC曲线如图
遇到的问题
修改了x值和y值读取后,带入网格搜索
1 | x = data_all.drop(columns=['status']).values |
遇到了如下提示
1 | /Users/windtrack/Interests/ai_related_learning/datawhale_dm_practice/.env/lib/python3.6/site-packages/sklearn/utils/validation.py:761: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel(). |
于是将
1 | clf = model.fit(x_train_standard, y_train) |
修改为
1 | clf = model.fit(x_train_standard, y_train.ravel()) |
后续改进方向
尝试更多的参数,同时发现当使用网格搜索时,部分参数取在了边缘,这说明参数搜索范围选取不好,需要重新选定