1. 任务背景
Datawhale组队学习中MySQL一周学习任务,通过一周组队自主学习,快速熟悉MySQL相关基础知识,并能掌握基本的数据查询操作方式
1.1 任务内容
- 导入示例数据库,教程 MySQL导入示例数据库 - MySQL教程™
- SQL是什么?MySQL是什么?
- 查询语句 SELECT FROM
- 语句解释
- 去重语句
- 前N个语句
- CASE...END判断语句
- 筛选语句 WHERE
- 语句解释
- 运算符/通配符/操作符
- 分组语句 GROUP BY
- 聚集函数
- 语句解释
- HAVING子句
- 排序语句 ORDER BY
- 语句解释
- 正序、逆序
- 函数
- 时间函数
- 数值函数
- 字符串函数
- SQL注释
- SQL代码规范
2. 导入示例数据库
2.1 通过MySQL命令导入
该任务提供了一个sql模板,我们更名为datawhale_day2_email.txt,并对其中建表部分,按照习惯进行了一定的修改
1 | CREATE TABLE IF NOT EXISTS `email` ( |
- 增加CREATE TABLE IF NOT EXISTS,这样只有当表不存在时才会去创建表
- 表名,字段名命名风格改为小写加下划线形式
- 为主键id设置为主键,并使其值为默认自增变量auto_increment
- 设置email字段不可为NULL,但为其添加默认值空字符串,这个习惯源于前公司的技术规定,所有字段都不可为空,但是可以设置默认值为空值
- 添加存储引擎InnoDB,设置默认编码格式为utf8mb4
2.1.1 使用source语句导入
source语句是在进入MySQL命令行以后执行的命令,将直接以命令行的形式执行整个SQL文件,首先还是先登录数据库,这里先暂时不指定数据库
1 | mysql -h127.0.0.1 -udatawhale_test -p |
由于txt文件中,未指定所使用的数据库,因此我们需要先选定数据库再执行SQL文件中的语句
1 | mysql> USE datawhale_mysql; |
原本以为必须用后缀名.sql的文件才能执行,现在看来不是,只要是文本文件即可;此外,对于source语句的位置,这个可以用相对路径,也就是相对于当前进入mysql的位置来执行
2.1.2 使用终端下的mysql命令导入
此时我们选用任务提供的另一个文件,并更名为datawhale_day2_big_country.txt,修改建表语句
1 | CREATE TABLE IF NOT EXISTS `world` ( |
因为添加了自增变量id,修改对应的插入语句,形如
1 | INSERT INTO world(`name`, `continent`, `area`, `population`, `gdp`) VALUES( 'Afghanistan', 'Asia',652230,25500100,20343000); |
在终端中输入以下命令
1 | mysql -h127.0.0.1 -udatawhale_test -p -Ddatawhale_mysql < datawhale_day2_big_country.txt |
此处输入密码后,无任何提示,此时我们进入MySQL后,可以看见语句时执行成功了
1 | mysql> show tables; |
2.2 通过DataGrip导入
此时我们先进入终端,删除此前通过datawhale_day2_email.txt生成的表和数据
1 | mysql> drop table email; |
打开DataGrip后,右键数据库名,选择Run SQL Script,选择对应文件即可
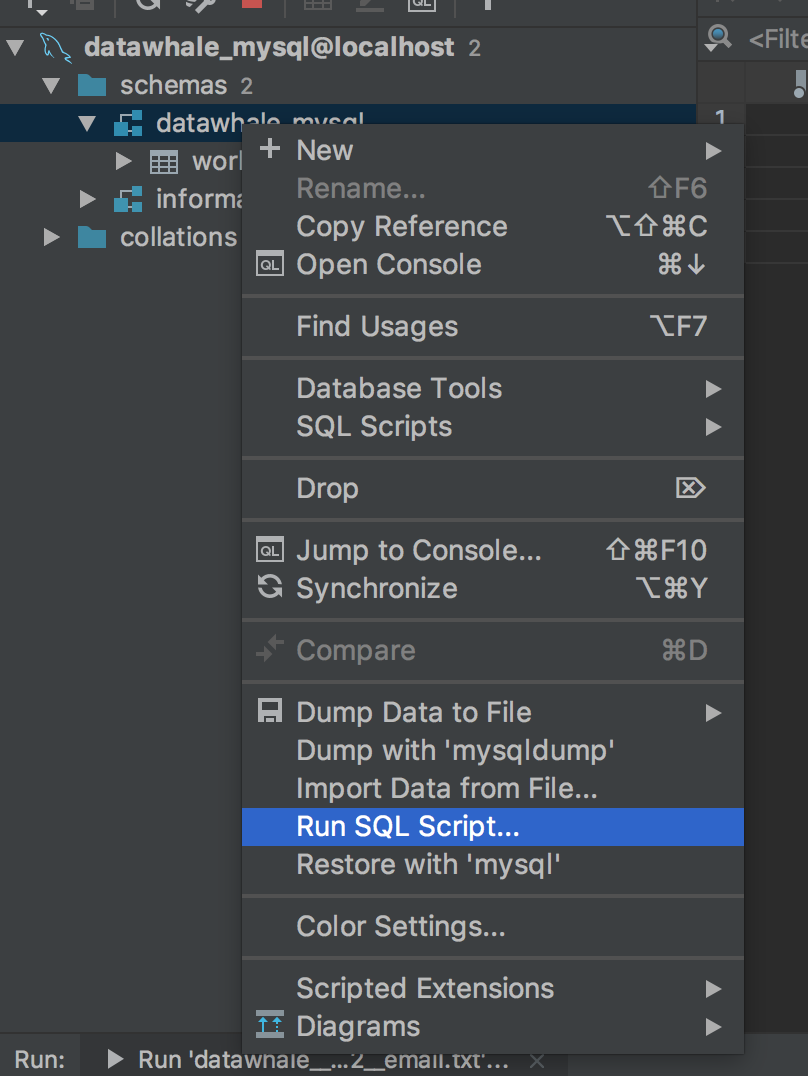
此时,便可以看见SQL语句已经执行完毕
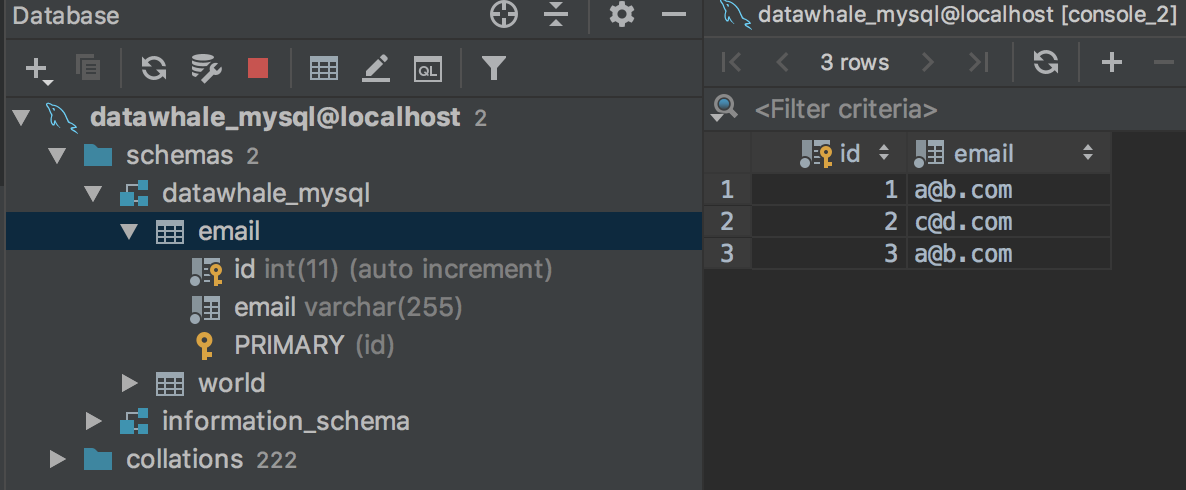
3. SQL与MySQL
3.1 SQL是什么
结构化查询语言(Structured Query Language)简称SQL(发音:/ˈes kjuː ˈel/ "S-Q-L"),是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。
结构化查询语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统, 可以使用相同的结构化查询语言作为数据输入与管理的接口。结构化查询语言语句可以嵌套,这使它具有极大的灵活性和强大的功能。
SQL包含三个部分:
3.2 MySQL是什么
MySQL is the world's most popular open source database. Whether you are a fast growing web property, technology ISV or large enterprise, MySQL can cost-effectively help you deliver high performance, scalable database applications.
My是MySQL的联合创始人 - Monty Widenius 的女儿的名字。MySQL是My和SQL的组合,这就是MySQL命名的由来。
MySQL的官方网址: http://www.mysql.com/ ,MySQL的社区版本下载地址为: http://dev.mysql.com/downloads/mysql/ 。
MySQL是一个数据库管理系统,也是一个关系数据库。它是由Oracle支持的开源软件。这意味着任何一个人都可以使用MySQL而不用支付一毛钱。 另外,如果需要,还可以更改其源代码或进行二次开发以满足您的需要。
即使MySQL是开源软件,但是可以从Oracle购买商业许可证版本,以获得高级支持服务(特殊企业用户需要)。
与其他数据库软件(如Oracle数据库或Microsoft SQL Server)相比,MySQL非常容易学习和掌握。
MySQL可以在各种平台上运行UNIX,Linux,Windows等。可以将其安装在服务器甚至桌面系统上。 此外,MySQL是可靠,可扩展和快速的。
4. 基本查询语句
4.1 SELECT FROM
SQL语句是由简单的英语单词构成的,这些单词称为关键字,每个 SQL语句都是由一个或多个关键字构成的。最经常使用的SQL语句大概就是 SELECT语句了,它的用途是从一个或多个表中检索信息。
4.1 SELECT语法
以下为MySQL5.7官方文档所给出的SELECT语法
1 | SELECT |
- Each select_expr indicates a column that you want to retrieve. There must be at least one select_expr.
- table_references indicates the table or tables from which to retrieve rows. Its syntax is described in Section 13.2.9.2, “JOIN Syntax”.
SELECTsupports explicit partition selection using thePARTITIONwith a list of partitions or subpartitions (or both) following the name of the table in a table_reference (see Section 13.2.9.2, “JOIN Syntax”). In this case, rows are selected only from the partitions listed, and any other partitions of the table are ignored. For more information and examples, see Section 22.5, “Partition Selection”.SELECT ... PARTITIONfrom tables using storage engines such asMyISAMthat perform table-level locks (and thus partition locks) lock only the partitions or subpartitions named by thePARTITIONoption. For more information, see Section 22.6.4, “Partitioning and Locking”.- The
WHEREclause, if given, indicates the condition or conditions that rows must satisfy to be selected. where_condition is an expression that evaluates to true for each row to be selected. The statement selects all rows if there is noWHEREclause. In theWHEREexpression, you can use any of the functions and operators that MySQL supports, except for aggregate (summary) functions. SeeSection 9.5, “Expressions”, and Chapter 12, Functions and Operators.
4.1.2 SELECT语句解释
1 | mysql> select name, continent, gdp from world where gdp > 100000000; |
- 从word表中,选取gdp大于100000000的行中列名为name、continet和gdp的数据
- 没有限定查询数目,也没限定排序规则,得到的会是满足where条件的所有数据的未排序状态,默认按先后插入顺序排列
- table_references中可以包含多个表,若包含多个表,select_expr和where_condition中需要指定列来自哪个表,若只有一个表,则无需额外指定
- 如果需要检索所有列,可以直接用*来表示,一般实际工作中是不允许这样做的
4.1.3 去重语句
如果需要对数据进行去重,可以用DISTINCT关键字
1 | mysql> SELECT DISTINCT continent from world; |
选取continent列中不重复的数据
1 | mysql> SELECT DISTINCT(continent), gdp from world; |
将DISTINCT针对continent加上括号,会发现查找出的continent并不唯一,我们插入一条数据,这条数据与此前id为5的数据在continent与gdp字段上并无差别,再次测试
1 | mysql> INSERT INTO world(`name`, `continent`, `area`, `population`, `gdp`) VALUES( 'Test' , 'Africa', 1246700, 20609294, 100990000); |
此时可以看出,DISTINCT关键字针对的是select_expr所有的列
4.1.4 前N个语句
原始全部查询
1 | mysql> select name, continent, gdp from world where gdp; |
只查询前3条
1 | mysql> select name, continent, gdp from world where gdp limit 3; |
offset可以设置偏移量,与传统编程一样,MySQL同样以0开始计数,OFFSET关键字默认为0,下面这句默认从偏移量为2(也就是第3条)开始,查询前3条数据
1 | mysql> select name, continent, gdp from world where gdp limit 3 offset 2; |
4.1.5 CASE…END判断语句
CASE…END是作为select_expr的一部分存在的
1 | mysql> SELECT name, continent, gdp, CASE WHEN gdp < 10000000 THEN 'small' WHEN gdp < 100000000 THEN 'middle' ELSE 'large' END AS description FROM world; |
可以类似解释为
1 | description = None |
需要注意的是,CASE后必须接着END来结束,不然会报错,如果没用ELSE,那么返回默认是NULL,此外上述用了个关键字AS,可以让列名更直观点,不然列名就会默认显示为“CASE WHEN gdp < 10000000 THEN 'small' WHEN gdp < 100000000 THEN 'middle' ELSE 'large' END”
4.2 筛选语句 WHERE
数据库表一般包含大量的数据,很少需要检索表中的所有行。通常只会根据特定操作或报告的需要提取表数据的子集。只检索所需数据需要指定搜索条件(search criteria),搜索条件也称为过滤条件(filter condition)。在SELECT语句中,数据根据WHERE子句中指定的搜索条件进行过滤。
4.2.1 操作符
| 操作符 | 说明 |
|---|---|
| = | 等于 |
| < > | 不等于 |
| != | 不等于 |
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| !< | 不小于 |
| >= | 大于等于 |
| !> | 不大于 |
| BETWEEN | 在指定的两个值之间 |
| IS NULL | 为NULL值 |
4.2.2 通配符
- 通配符(wildcard)
- 用来匹配值的一部分的特殊字符。
- 搜索模式(search pattern)
- 由字面值、通配符或两者组合构成的搜索条件
通配符本身实际上是 SQL的WHERE子句中有特殊含义的字符,SQL支持几种通配符。为在搜索子句中使用通配符,必须使用LIKE操作符。LIKE指示 DBMS,后跟的搜索模式利用通配符匹配而不是简单的相等匹配进行比较。
最常使用的通配符是百分号(%)。在搜索串中,%表示任何字符出现任意次数,也可以出现0次
1 | mysql> SELECT name, continent, gdp FROM world WHERE name LIKE 'A%'; |
表示匹配中name列以A开头的所有行
下划线通配符(_)只匹配单个字符,有且出现1次
1 | mysql> SELECT name, continent, gdp FROM world WHERE name LIKE 'A_bania'; |
方括号([])通配符在MySQL中与MSSQL不太一样,属于正则模式
1 | mysql> SELECT name, continent, gdp FROM world WHERE name REGEXP '[tln]'; |
此语句表示,匹配name中,包含有tln任意字母的行
4.3 分组语句 GROUP BY
4.3.1 创建分组
在使用GROUP BY子句前,需要知道一些重要的规定。
- GROUP BY子句可以包含任意数目的列,因而可以对分组进行嵌套,更细致地进行数据分组。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后指定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
- GROUP BY子句中列出的每一列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUPBY子句中指定相同的表达式。不能使用别名。
- 大多数 SQL实现不允许GROUP BY列带有长度可变的数据类型(如文本或备注型字段)。
- 除聚集计算语句外,SELECT语句中的每一列都必须在GROUPBY子句中给出。
- 如果分组列中包含具有NULL值的行,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前
1 | mysql> SELECT continent, COUNT(*) FROM world GROUP BY continent; |
查找world表中,按continent字段分组,以及对应的行数
4.3.2 过滤分组
除了能用 GROUP BY分组数据外,SQL还允许过滤分组,规定包括哪些分组,排除哪些分组。
WHERE过滤指定的是行而不是分组,事实上,WHERE没有分组的概念。那么,不使用 WHERE使用什么呢?SQL为此提供了另一个子句,就是HAVING子句,HAVING非常类似于WHERE。事实上,目前为止所学过的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是,WHERE过滤行,而HAVING过滤分组。
1 | mysql> SELECT continent, COUNT(*) FROM world GROUP BY continent HAVING COUNT(*) > 1; |
查找world表中,按continent字段分组,以及对应的行数,并过滤只显示对应条数大于1的数据
说明:HAVING 和 WHERE 的差别这里有另一种理解方法,WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响 HAVING子句中基于这些值过滤掉的分组。
4.4 排序语句 ORDER BY
1 | mysql> SELECT continent, COUNT(*) FROM world GROUP BY continent HAVING COUNT(*) > 1 ORDER BY COUNT(*) DESC; |
在前一条过滤的基础上,按照对应行数逆序排序,DESC表示逆序,默认不加为正序
4.5 函数
与大多数其他计算机语言一样,SQL也可以用函数来处理数据。函数一般是在数据上执行的,为数据的转换和处理提供了方便。
与 SQL语句不一样,SQL函数不是可移植的。这意味着为特定 SQL实现编写的代码在其他实现中可能不正常。
大多数 SQL实现支持以下类型的函数,
- 用于处理文本字符串(如删除或填充值,转换值为大写或小写)的文本函数。
- 用于在数值数据上进行算术操作(如返回绝对值,进行代数运算)的数值函数。
- 用于处理日期和时间值并从这些值中提取特定成分(如返回两个日期之差,检查日期有效性)的日期和时间函数。
- 返回 DBMS正使用的特殊信息(如返回用户登录信息)的系统函数。
4.5.1 字符串函数
| Name | Description |
|---|---|
ASCII() |
Return numeric value of left-most character |
BIN() |
Return a string containing binary representation of a number |
BIT_LENGTH() |
Return length of argument in bits |
CHAR() |
Return the character for each integer passed |
CHAR_LENGTH() |
Return number of characters in argument |
CHARACTER_LENGTH() |
Synonym for CHAR_LENGTH() |
CONCAT() |
Return concatenated string |
CONCAT_WS() |
Return concatenate with separator |
ELT() |
Return string at index number |
EXPORT_SET() |
Return a string such that for every bit set in the value bits, you get an on string and for every unset bit, you get an off string |
FIELD() |
Index (position) of first argument in subsequent arguments |
FIND_IN_SET() |
Index (position) of first argument within second argument |
FORMAT() |
Return a number formatted to specified number of decimal places |
FROM_BASE64() |
Decode base64 encoded string and return result |
HEX() |
Hexadecimal representation of decimal or string value |
INSERT() |
Insert substring at specified position up to specified number of characters |
INSTR() |
Return the index of the first occurrence of substring |
LCASE() |
Synonym for LOWER() |
LEFT() |
Return the leftmost number of characters as specified |
LENGTH() |
Return the length of a string in bytes |
LIKE |
Simple pattern matching |
LOAD_FILE() |
Load the named file |
LOCATE() |
Return the position of the first occurrence of substring |
LOWER() |
Return the argument in lowercase |
LPAD() |
Return the string argument, left-padded with the specified string |
LTRIM() |
Remove leading spaces |
MAKE_SET() |
Return a set of comma-separated strings that have the corresponding bit in bits set |
MATCH |
Perform full-text search |
MID() |
Return a substring starting from the specified position |
NOT LIKE |
Negation of simple pattern matching |
NOT REGEXP |
Negation of REGEXP |
OCT() |
Return a string containing octal representation of a number |
OCTET_LENGTH() |
Synonym for LENGTH() |
ORD() |
Return character code for leftmost character of the argument |
POSITION() |
Synonym for LOCATE() |
QUOTE() |
Escape the argument for use in an SQL statement |
REGEXP |
Whether string matches regular expression |
REPEAT() |
Repeat a string the specified number of times |
REPLACE() |
Replace occurrences of a specified string |
REVERSE() |
Reverse the characters in a string |
RIGHT() |
Return the specified rightmost number of characters |
RLIKE |
Whether string matches regular expression |
RPAD() |
Append string the specified number of times |
RTRIM() |
Remove trailing spaces |
SOUNDEX() |
Return a soundex string |
SOUNDS LIKE |
Compare sounds |
SPACE() |
Return a string of the specified number of spaces |
STRCMP() |
Compare two strings |
SUBSTR() |
Return the substring as specified |
SUBSTRING() |
Return the substring as specified |
SUBSTRING_INDEX() |
Return a substring from a string before the specified number of occurrences of the delimiter |
TO_BASE64() |
Return the argument converted to a base-64 string |
TRIM() |
Remove leading and trailing spaces |
UCASE() |
Synonym for UPPER() |
UNHEX() |
Return a string containing hex representation of a number |
UPPER() |
Convert to uppercase |
WEIGHT_STRING() |
Return the weight string for a string |
4.5.2 日期与时间函数
| Name | Description |
|---|---|
ADDDATE() |
Add time values (intervals) to a date value |
ADDTIME() |
Add time |
CONVERT_TZ() |
Convert from one time zone to another |
CURDATE() |
Return the current date |
CURRENT_DATE(),
CURRENT_DATE |
Synonyms for CURDATE() |
CURRENT_TIME(),
CURRENT_TIME |
Synonyms for CURTIME() |
CURRENT_TIMESTAMP(),
CURRENT_TIMESTAMP |
Synonyms for NOW() |
CURTIME() |
Return the current time |
DATE() |
Extract the date part of a date or datetime expression |
DATE_ADD() |
Add time values (intervals) to a date value |
DATE_FORMAT() |
Format date as specified |
DATE_SUB() |
Subtract a time value (interval) from a date |
DATEDIFF() |
Subtract two dates |
DAY() |
Synonym for DAYOFMONTH() |
DAYNAME() |
Return the name of the weekday |
DAYOFMONTH() |
Return the day of the month (0-31) |
DAYOFWEEK() |
Return the weekday index of the argument |
DAYOFYEAR() |
Return the day of the year (1-366) |
EXTRACT() |
Extract part of a date |
FROM_DAYS() |
Convert a day number to a date |
FROM_UNIXTIME() |
Format Unix timestamp as a date |
GET_FORMAT() |
Return a date format string |
HOUR() |
Extract the hour |
LAST_DAY |
Return the last day of the month for the argument |
LOCALTIME(),
LOCALTIME |
Synonym for NOW() |
LOCALTIMESTAMP,
LOCALTIMESTAMP() |
Synonym for NOW() |
MAKEDATE() |
Create a date from the year and day of year |
MAKETIME() |
Create time from hour, minute, second |
MICROSECOND() |
Return the microseconds from argument |
MINUTE() |
Return the minute from the argument |
MONTH() |
Return the month from the date passed |
MONTHNAME() |
Return the name of the month |
NOW() |
Return the current date and time |
PERIOD_ADD() |
Add a period to a year-month |
PERIOD_DIFF() |
Return the number of months between periods |
QUARTER() |
Return the quarter from a date argument |
SEC_TO_TIME() |
Converts seconds to 'HH:MM:SS' format |
SECOND() |
Return the second (0-59) |
STR_TO_DATE() |
Convert a string to a date |
SUBDATE() |
Synonym for DATE_SUB() when invoked with three arguments |
SUBTIME() |
Subtract times |
SYSDATE() |
Return the time at which the function executes |
TIME() |
Extract the time portion of the expression passed |
TIME_FORMAT() |
Format as time |
TIME_TO_SEC() |
Return the argument converted to seconds |
TIMEDIFF() |
Subtract time |
TIMESTAMP() |
With a single argument, this function returns the date or datetime expression; with two arguments, the sum of the arguments |
TIMESTAMPADD() |
Add an interval to a datetime expression |
TIMESTAMPDIFF() |
Subtract an interval from a datetime expression |
TO_DAYS() |
Return the date argument converted to days |
TO_SECONDS() |
Return the date or datetime argument converted to seconds since Year 0 |
UNIX_TIMESTAMP() |
Return a Unix timestamp |
UTC_DATE() |
Return the current UTC date |
UTC_TIME() |
Return the current UTC time |
UTC_TIMESTAMP() |
Return the current UTC date and time |
WEEK() |
Return the week number |
WEEKDAY() |
Return the weekday index |
WEEKOFYEAR() |
Return the calendar week of the date (1-53) |
YEAR() |
Return the year |
YEARWEEK() |
Return the year and week |
4.5.3 数值函数
| Name | Description |
|---|---|
ABS() |
Return the absolute value |
ACOS() |
Return the arc cosine |
ASIN() |
Return the arc sine |
ATAN() |
Return the arc tangent |
ATAN2(),
ATAN() |
Return the arc tangent of the two arguments |
CEIL() |
Return the smallest integer value not less than the argument |
CEILING() |
Return the smallest integer value not less than the argument |
CONV() |
Convert numbers between different number bases |
COS() |
Return the cosine |
COT() |
Return the cotangent |
CRC32() |
Compute a cyclic redundancy check value |
DEGREES() |
Convert radians to degrees |
EXP() |
Raise to the power of |
FLOOR() |
Return the largest integer value not greater than the argument |
LN() |
Return the natural logarithm of the argument |
LOG() |
Return the natural logarithm of the first argument |
LOG10() |
Return the base-10 logarithm of the argument |
LOG2() |
Return the base-2 logarithm of the argument |
MOD() |
Return the remainder |
PI() |
Return the value of pi |
POW() |
Return the argument raised to the specified power |
POWER() |
Return the argument raised to the specified power |
RADIANS() |
Return argument converted to radians |
RAND() |
Return a random floating-point value |
ROUND() |
Round the argument |
SIGN() |
Return the sign of the argument |
SIN() |
Return the sine of the argument |
SQRT() |
Return the square root of the argument |
TAN() |
Return the tangent of the argument |
TRUNCATE() |
Truncate to specified number of decimal places |
5. SQL注释
MySQL注释一共有三种方法
5.1 单行注释可以用"#"
1 | mysql> SELECT 1 AS test; # This is a method to comment single row |
5.2 单行注释的第二种写法用 "-- "
注意这个风格下"--【空格】" 也就是说“--" 与注释之间是有空格的
1 | mysql> SELECT 1 AS test; -- This is another method to comment single row |
5.3 多行注释可以用/**/
1 | mysql> SELECT 1 AS test; /* This is a method to comment |
6. SQL代码规范
6.1 命名的建议
- 使用统一的、描述性强的字段命名规则
- 保证字段名是独一无二且不是保留字的,不要使用连续的下划线,不用下划线结尾
- 最好以字母开头
6.2 格式建议
最好使用标准SQL函数而不是特定供应商Oracle、Mysql等的函数以提高可移植性
大小写的运用,系统关键字大写,字段表名小写
灵活使用空格和缩进来增强可读性——两大法宝空白隔道与垂直间距
- 利用空格保持关键字对齐
- 在等号前后(=)在逗号后(,)单引号前后(')加上空格
- 子查询缩进并对齐
6.3 语法建议
- 尽量使用BETWEEN而不是多个AND
- 同样,使用 IN 而不是多个OR
- 利用CASE语句嵌套处理更复杂的逻辑结构
- 避免UNION语句与临时表
6.4 推荐工具
可以使用SQLinForm来转换自己的SQL格式
7. 作业
7.1 作业一
1 | 项目一:查找重复的电子邮箱(难度:简单) |
分析题意,即选取存在重复email的数据,可以先将email分组,然后找出对应数据多于1条的数据,也就是GROUP BY 与 HAVING 语句的组合使用
1 | mysql> SELECT email FROM email GROUP BY email HAVING COUNT(*) > 1; |
7.2 作业二
1 | 项目二:查找大国(难度:简单) |
这个就是个基本的SQL WHERE使用,类似a and ( b or c ) 查找
1 | mysql> SELECT name, population, area FROM world WHERE area > 3000000 OR (population > 25000000 AND gdp > 20000000); |